MCP Gateway: Centralized API Gateway for Model Context Protocol
Impact Summary
Built a centralized gateway in Go that lets LLM clients reach multiple MCP servers through a single endpoint, with namespace isolation, per-key access controls, tool-level filtering, and embedded analytics powered by DuckDB.
Role
Creator & Maintainer
Timeline
2024-Present
Scale
- Multi-tenant with namespace isolation
- 88.8% test coverage
- Embedded DuckDB analytics
- SSE streaming proxy
Links
Decision Summary
- • Must add minimal latency to real-time LLM tool calls
- • Analytics must be embedded, no external database to install or manage
- • Must preserve SSE streaming for MCP protocol compatibility
- • Configuration must be declarative and environment-aware
- • Must support multi-tenant access with per-key restrictions
- + Single binary deployment, DuckDB embedded means zero external deps
- + Go concurrency model handles many simultaneous SSE streams efficiently
- + Namespace routing gives clean multi-tenant separation
- + Analytics built in from day one, not bolted on later
- − Custom gateway means maintaining routing and proxy logic
- − DuckDB is embedded, so analytics are local to the gateway instance
- + Battle-tested HTTP proxy, widely understood
- + High throughput with minimal resource usage
- − Lua scripting for auth and filtering is fragile and hard to test
- − No built-in analytics, would need a separate logging pipeline
- − SSE streaming support requires careful configuration
- + Rich observability and traffic management out of the box
- + mTLS and policy enforcement built in
- − Massive operational overhead for what is essentially a tool proxy
- − Kubernetes-centric, overkill for most MCP deployments
- − Tool-level filtering would still require custom filters
The Problem
MCP is quickly becoming the standard way LLM applications connect to external tools. But the moment you have more than one or two MCP servers, the operational picture gets ugly. Each server is its own endpoint with its own configuration. Each LLM client needs credentials for every server it talks to. There is no central place to see what tools are being called, no way to restrict which users can access which tools, and no unified authentication layer.
I ran into this firsthand. I had a filesystem MCP server, a search server, and a couple of domain-specific servers, and each one was a separate integration point. Adding a new client meant configuring four endpoints, distributing four sets of credentials, and hoping nobody fat-fingered a URL. Monitoring was nonexistent. If something broke at 2am, I had no logs to tell me which server, which tool, or which client was involved.
The conventional answer would be “put nginx in front of it” or “throw it into a service mesh.” But nginx gives you routing without understanding. It doesn’t know what an MCP tool is, so it can’t filter at the tool level. And a full service mesh is a sledgehammer for a nail. I needed something purpose-built: a gateway that speaks MCP natively and provides the authentication, routing, filtering, and analytics that production deployments actually require.
The Approach
Namespace-Based Routing
The core abstraction is the namespace. Each backend MCP server gets a namespace prefix. A client calling /mcp/filesystem/tools/list hits the filesystem server. A call to /mcp/search/tools/call hits the search server. The gateway resolves the namespace, strips the prefix, and forwards the JSON-RPC request to the appropriate backend.
This keeps the routing logic simple and declarative. Adding a new MCP server means adding a few lines to the YAML config, not writing new code. The namespace also becomes the natural boundary for access control: an API key can be restricted to specific namespaces, so a client that should only access search tools never sees the filesystem server.
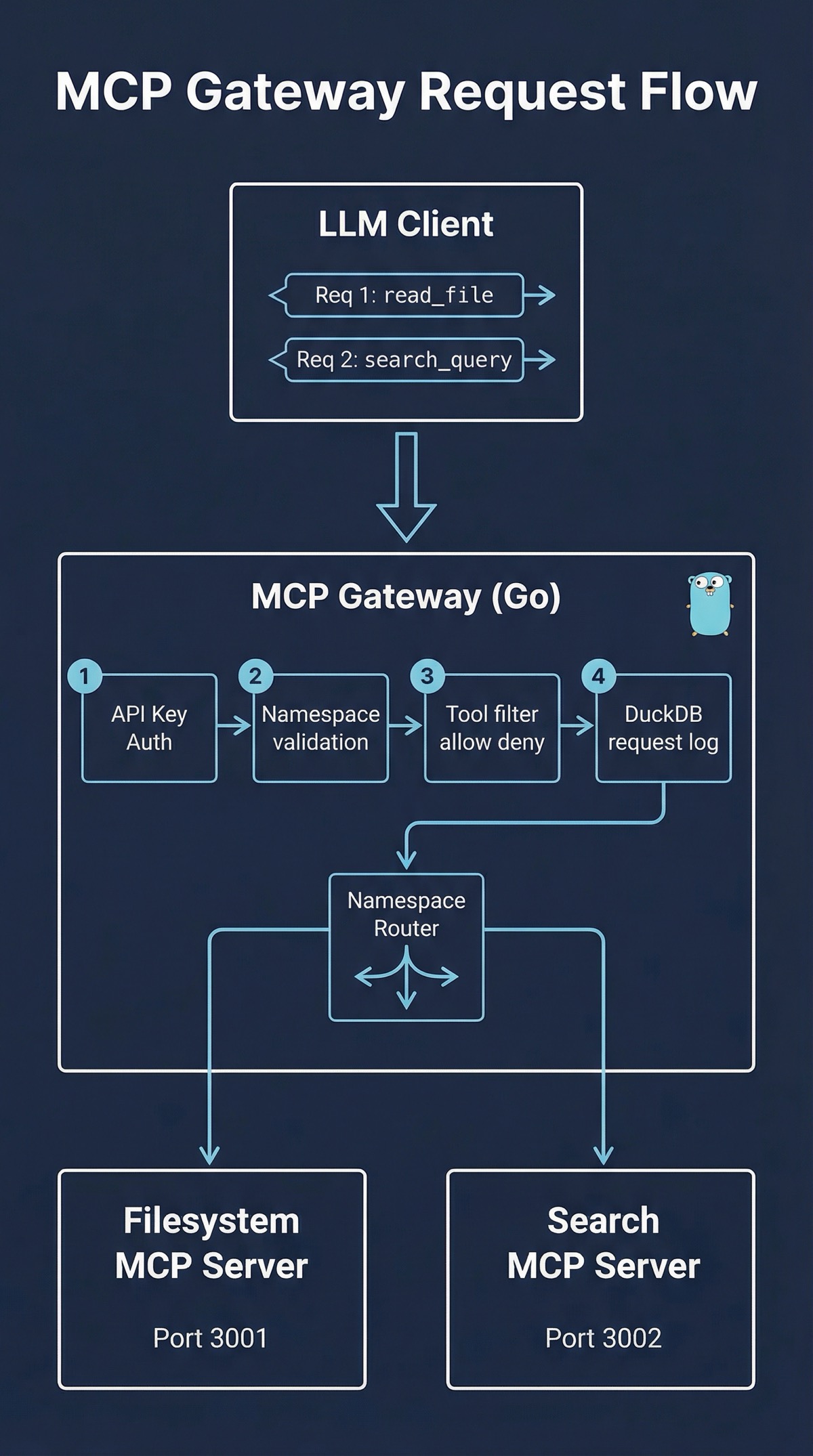
API Key Authentication with Namespace Restrictions
Every request requires an API key. Each key is configured with a list of allowed namespaces. A key might have access to search and analytics but not filesystem. The middleware validates the key, checks the namespace against the key’s allowed list, and rejects unauthorized requests before they reach the backend.
This is deliberately simpler than OAuth or JWT. MCP tool calls are machine-to-machine. The clients are LLM applications, not humans clicking through a browser. API keys with namespace scoping hit the right balance: straightforward to implement, easy to rotate, and granular enough for real access control.
Tool Filtering
Namespace restrictions control which servers a key can reach. Tool filtering goes one level deeper: it controls which specific tools within a namespace are available. Each namespace can have an allow list or a deny list of tool names.
This matters in practice. You might expose a filesystem MCP server but want to block the write_file tool for most clients. Or you might have a powerful admin namespace but want to deny delete_database for all but one key. The allow/deny model handles both cases without complicating the routing layer.
Embedded Analytics with DuckDB
I wanted analytics from day one, not as a follow-up feature. Every request that passes through the gateway gets logged: timestamp, API key, namespace, tool name, response status, and latency. These logs go into DuckDB, an embedded analytical database that ships as a Go library.
DuckDB was the key decision here. It requires zero installation. There is no separate database process, no connection string, no migration tooling. It just works as part of the gateway binary. And because DuckDB is columnar and optimized for analytical queries, it handles the access patterns I cared about efficiently: aggregations over time windows, tool popularity rankings, per-key usage breakdowns.
The analytics API exposes this data through REST endpoints. You can query total requests by namespace, get the top tools by invocation count, or pull time-series data for dashboards. It turns the gateway from a dumb proxy into an observability layer for your MCP infrastructure.
SSE Streaming Proxy
MCP uses Server-Sent Events for streaming responses. The gateway needs to handle these correctly, which means it can’t just buffer the backend response and forward it. It has to proxy the SSE stream in real time, preserving event boundaries and keeping the connection alive.
The Go implementation uses goroutines to read from the backend SSE stream and write to the client connection concurrently. Flush control ensures events are pushed to the client as they arrive rather than batched by the HTTP buffer. This preserves the real-time behavior that MCP clients expect.
Configuration
The entire gateway is configured through a single YAML file. Server addresses, namespace mappings, API keys, tool filters, analytics settings, all declared in one place. Environment variable expansion (${VAR_NAME}) is supported throughout, so secrets stay out of the config file and deployment-specific values can be injected at runtime.
namespaces:
filesystem:
upstream: "http://localhost:3001"
tools:
deny: ["write_file", "delete_file"]
search:
upstream: "http://localhost:3002"
auth:
keys:
- key: "${MCP_API_KEY_READONLY}"
namespaces: ["search"]
- key: "${MCP_API_KEY_ADMIN}"
namespaces: ["filesystem", "search"]Testing
The project shipped with 88.8% test coverage from the initial commit. Unit tests cover the routing logic, authentication middleware, tool filtering, and analytics queries. Integration tests spin up test MCP servers and verify end-to-end request flows through the gateway. Test fixtures provide reproducible scenarios for edge cases like malformed JSON-RPC requests, expired API keys, and SSE connection drops.
I’m particular about test coverage in infrastructure code. A gateway is a single point of failure by definition. If it has a bug in the routing logic or a race condition in the SSE proxy, every client is affected. 88.8% coverage doesn’t guarantee correctness, but it means the critical paths have been exercised and the obvious failure modes are covered.
What I Learned
Embedded databases change the deployment calculus. Before DuckDB, adding analytics to a gateway meant introducing a database dependency. That’s a migration tool, a connection pool, a health check, and a failure mode. Embedding the database eliminates all of that. The gateway is still a single binary. This shifted my thinking about when to include analytics: if the cost is near zero, you should include it from the start rather than retrofitting it later.
Namespace-based routing is underrated. URL-prefix routing is one of the oldest patterns in web infrastructure, and it maps perfectly onto multi-server MCP deployments. The namespace gives you routing, access control boundaries, and tool filtering scopes all in one concept. Every time I considered a more complex routing scheme (header-based, content-based, service discovery), the namespace approach was simpler and sufficient.
Tool-level filtering is the gap in generic proxies. Nginx can route by path. A service mesh can enforce mTLS. But neither knows what an MCP tool is. The ability to say “this key can access the filesystem namespace but not the write_file tool” requires a gateway that understands the MCP protocol. This is the core reason a purpose-built gateway exists rather than stacking config on a generic reverse proxy.
SSE proxying is trickier than it looks. HTTP proxies typically buffer responses. SSE requires the opposite: events must be flushed immediately. Getting this right in Go meant explicit flush control, careful goroutine lifecycle management, and proper cleanup when either side of the connection drops. The streaming proxy logic is some of the most carefully tested code in the project.
Ship comprehensive from day one. The entire project landed in a single initial commit: routing, auth, tool filtering, analytics, SSE streaming, configuration, and 88.8% test coverage. Building it all together meant the pieces were designed to fit. If I had shipped routing first and bolted on analytics later, the request logging would have been an afterthought rather than a first-class concern woven through the middleware pipeline.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/mcp-gateway
Star it, fork it, or open an issue — contributions and feedback welcome.
Related Projects
AWS Security Group Mapper: Visual Analysis Tool for Cloud Security
A Python tool for visualizing AWS security group relationships and generating interactive graphs to help understand complex security architectures.
Fighters Paradise: Modern Game Engine Reimplementation in Rust
A modern Rust reimplementation of the MUGEN 2D fighting game engine with full backward compatibility for existing community content.
Agent-Eval: CI Evaluation Harness for Multi-Agent Development
Behavioral regression testing framework for detecting drift in AI agent instruction files across multi-agent development environments.