Plan, Claim, Apply: Building fakoli-state
A local-first project-state layer in SQLite, with claims that have heartbeats and evidence captured by hooks. Here's how it was built and which trade-offs I'm still living with.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer.
Part 1 was the argument: workflow orchestration alone won’t save you, and the layer that breaks first is the project state. This is the blueprint for what I built.
I want to walk through this the way I’d walk through any infrastructure design — choices first, alternatives rejected, trade-offs accepted. The state layer of an agentic system has the same shape as any other state layer, which means the same boring questions matter: where does it live, who can write it, what happens when it’s stale, how do you recover. I’m going to answer those in roughly the order I had to answer them while building.
A short tour first, then the design choices one by one.
The Terraform Analogy That Wouldn’t Leave Me Alone
The mental model I kept coming back to was Terraform. Not because I was looking for it. Because every design question I asked landed on an answer that Terraform had already given.
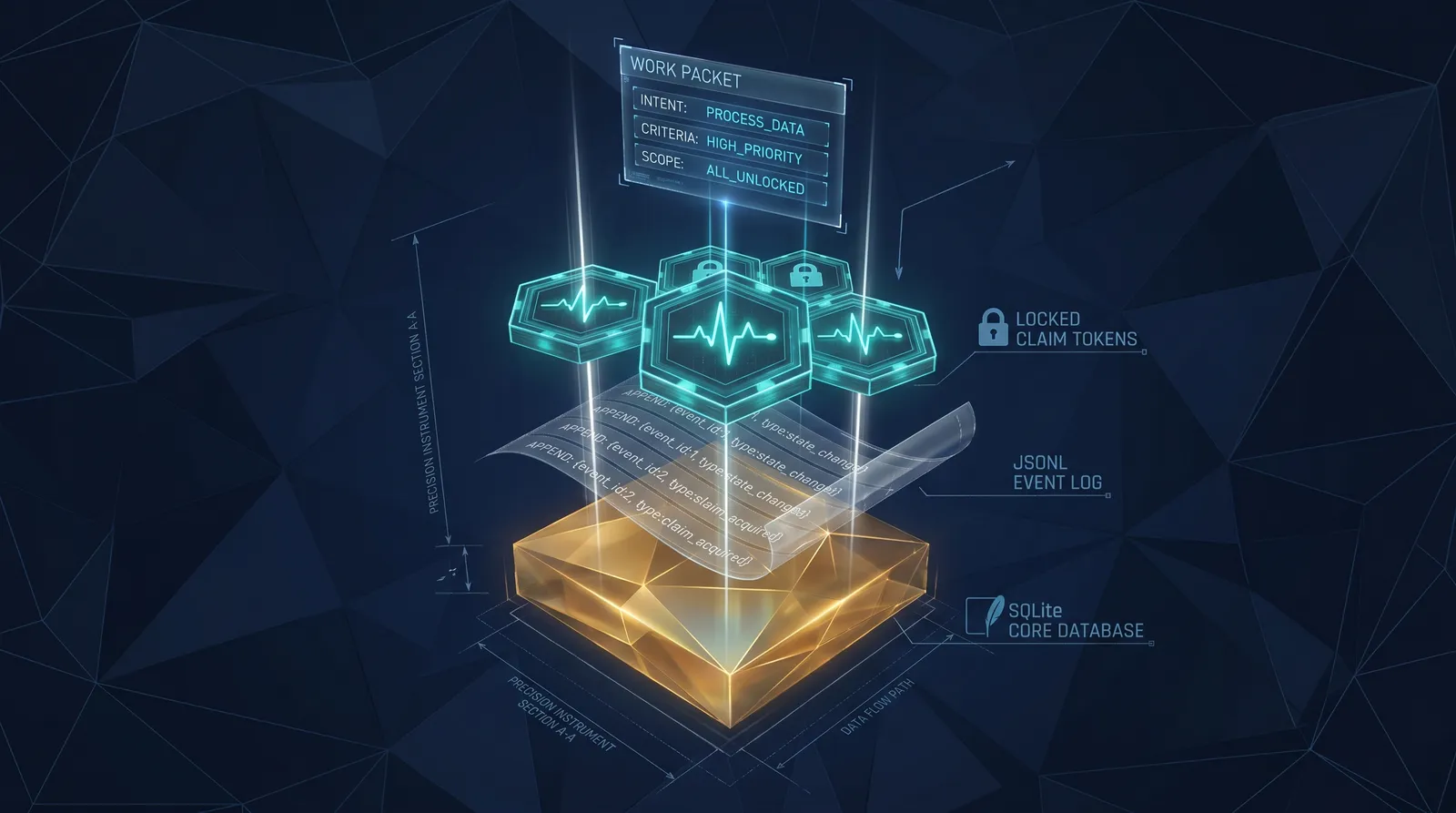
The PRD is the configuration. The parsed requirements, features, and tasks are the resources the configuration declares. The SQLite database is the state file. The work packet is terraform plan — a derived view of what’s about to happen, regenerated from canonical truth on demand, never the source of truth itself. The apply step is the commit point where reviewed work transitions from accepted to done with an audit row attached. Stale claims are drift. Force-release is the operator override. Sync providers are the projection layer — turning canonical state into something an external system (GitHub Issues, eventually Linear) can read.
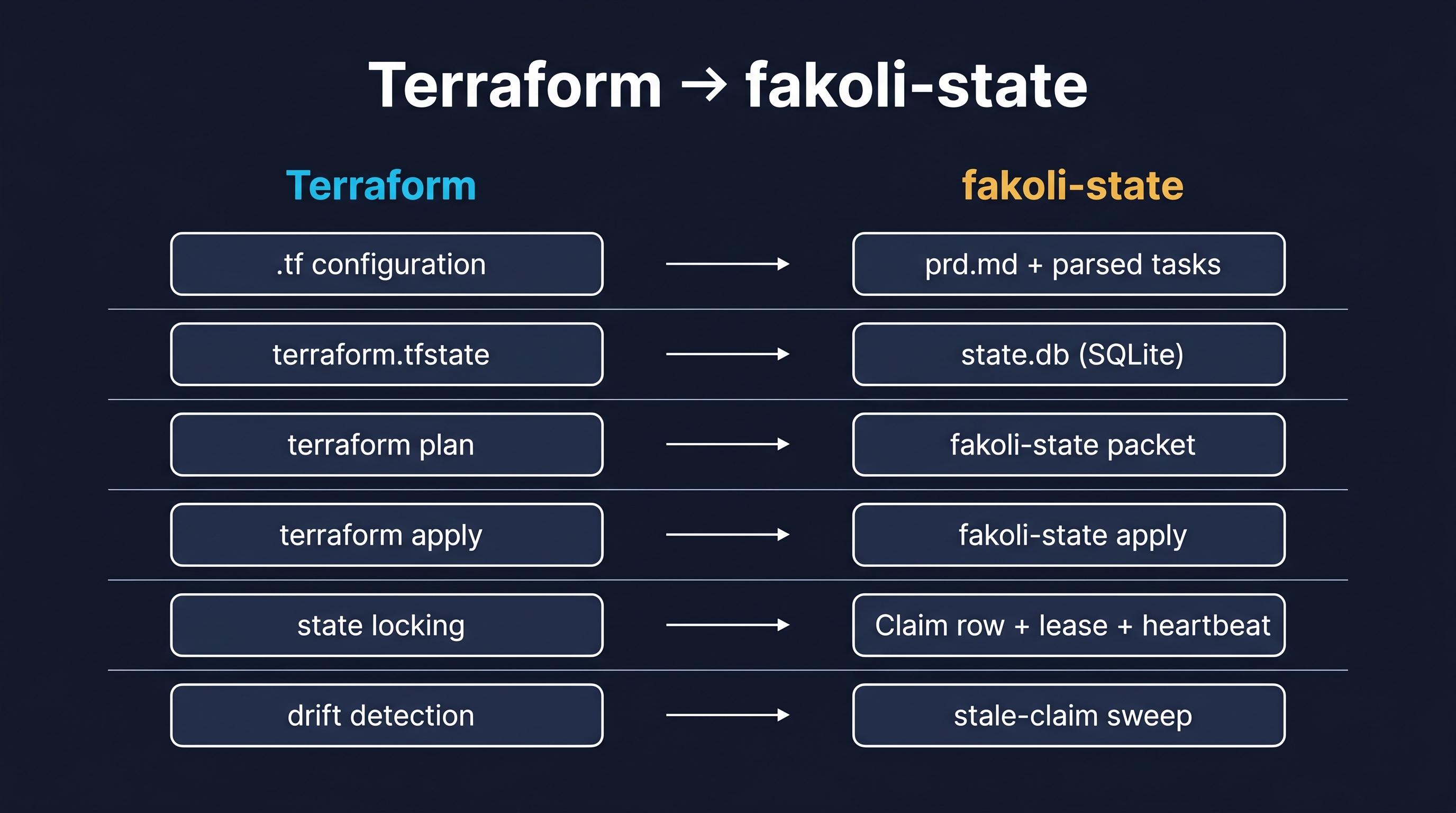
Once I let the analogy do the work, the design wrote itself. Plan before apply. Canonical state separate from derived views. Drift detected and reported, never papered over. Backend abstraction in the codebase but only one battle-tested impl shipping. The discipline that makes Terraform trustworthy is the same discipline that makes shared agentic state trustworthy: the state file is the truth and everything else is downstream.
The places the analogy breaks are also instructive. Terraform owns the resources it manages — it can destroy them, it can drift-correct them, it can refuse to proceed if something’s wrong. fakoli-state doesn’t own source code; it records that an agent edited a file and what evidence the agent produced. There’s no destroy verb because there’s no resource graph to tear down. There’s no import because empty repos don’t have state to discover — init creates an empty workspace and the PRD authoring flow populates it.
I’m being specific about this because the analogy decides what gets built and what doesn’t. The features I rejected — a hosted dashboard, a long-running daemon, a CRDT-based collaboration model — all failed the Terraform test: would a Terraform project ship this? They wouldn’t. So I didn’t.
The Trinity, Made Explicit
Before I get into the engine, the position the state layer holds across the trinity. fakoli-flow is the workflow plugin — it defines how work moves through the pipeline (brainstorm, plan, execute, verify, finish). fakoli-crew is the specialists plugin — it defines who does the work (guido, critic, sentinel, scout, smith, welder, herald, keeper). fakoli-state is the third piece, and it defines what is true.
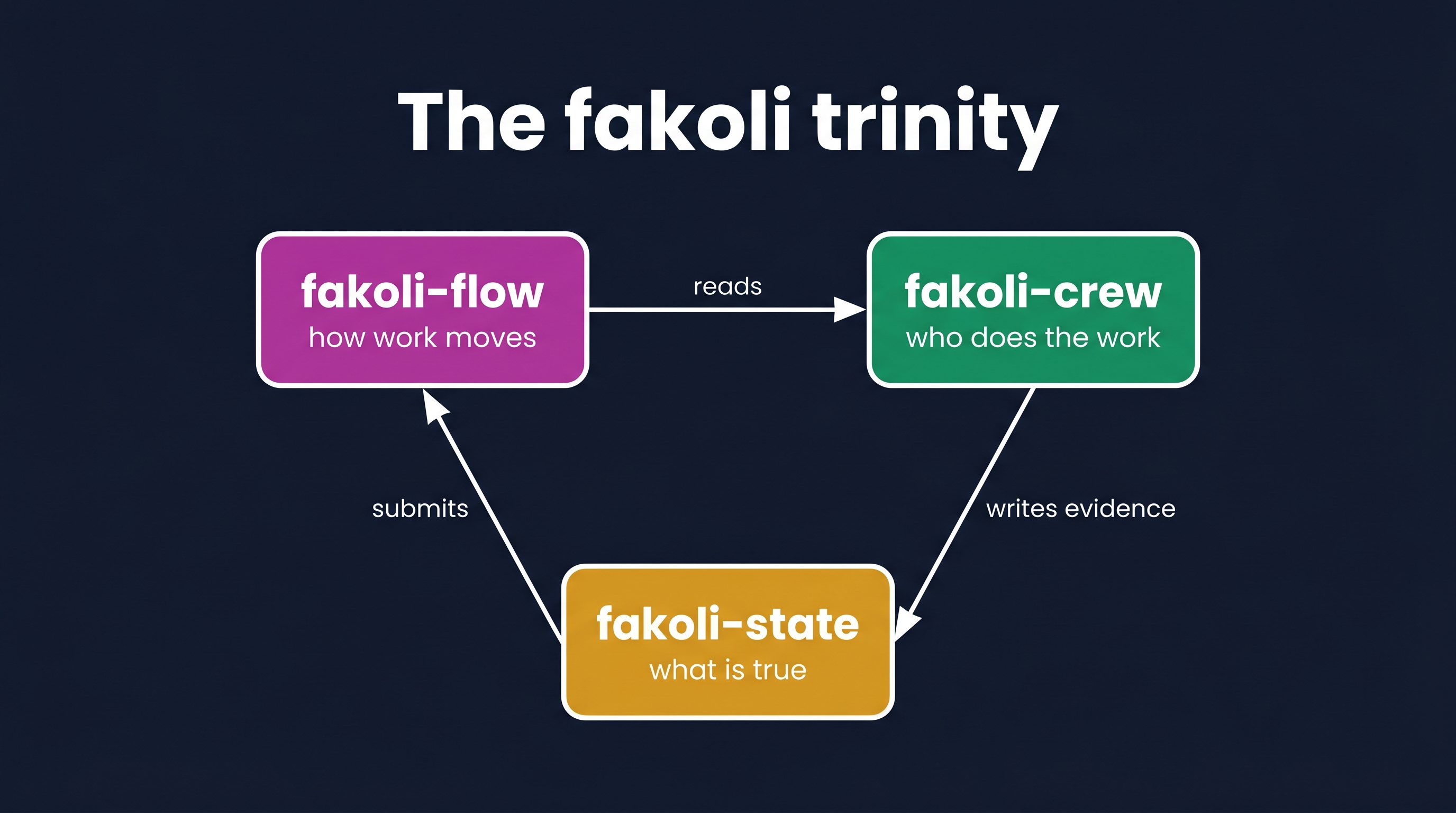
When the three are installed together, flow and crew compose around state. flow:execute calls fakoli-state next to pick the right task, calls fakoli-state claim before dispatching a crew specialist, and calls fakoli-state submit with the evidence instead of writing a markdown status file. flow:verify calls fakoli-state status and routes the sentinel only at tasks with submitted evidence. flow:finish calls fakoli-state apply before any merge or PR.
When state isn’t installed, flow and crew fall back to their markdown-status conventions. Integration is opt-in throughout. That property mattered to me: I didn’t want state to be a hard dependency for users who only need workflow scaffolding, and I didn’t want the workflow plugin to become unusable for someone who hadn’t yet adopted the state layer.
The State Engine
SQLite, one database per project at .fakoli-state/state.db, opened in WAL mode. Append-only JSONL event log alongside it at .fakoli-state/events.jsonl. Pydantic v2 models for every entity, validated at every transition.
The reason for SQLite over the alternatives:
Postgres. Requires a server, credentials, network. Kills the “clone the repo and fakoli-state init” demo. The wedge is local-first; a hosted DB is a different product.
File-only JSON or YAML. The first instinct. Rejected for three reasons: cross-process atomic writes on plain JSON race on macOS and on Windows; claim leases need BEGIN IMMEDIATE transaction semantics that JSON cannot provide; and querying becomes O(n) over the entire file on every CLI invocation, which adds up fast for a system that wants its hooks to complete in under 200 milliseconds.
Redis or in-memory. Loses durability across CLI invocations. Each invocation is a short-lived process — there’s no daemon. Loses the audit trail. Forces a sidecar process. Wrong shape.
WAL mode specifically because the default SQLite journaling mode holds an exclusive lock during writes, blocking all readers. WAL lets readers proceed concurrently with a single writer. For my actual workload — many fakoli-state status reads from hooks, occasional fakoli-state claim writes from agents — WAL is the right pick. I pay a wal and wal-shm sidecar file cost in .fakoli-state/; both are gitignored.
The event log alongside the database is the audit guarantee. Every state mutation appends a JSONL row to events.jsonl. Replaying the log from scratch against an empty database reconstructs state.db byte-for-byte. That’s not just a backup story — it’s the property that lets the SQLite file itself be gitignored on projects that don’t want binary merge conflicts, because the event log can be committed and replay rebuilds the DB on the next machine.
The Lifecycle, From PRD to Done
Here’s what a task actually looks like as it moves through the system. This is the path I walk myself through whenever someone asks me what fakoli-state does.
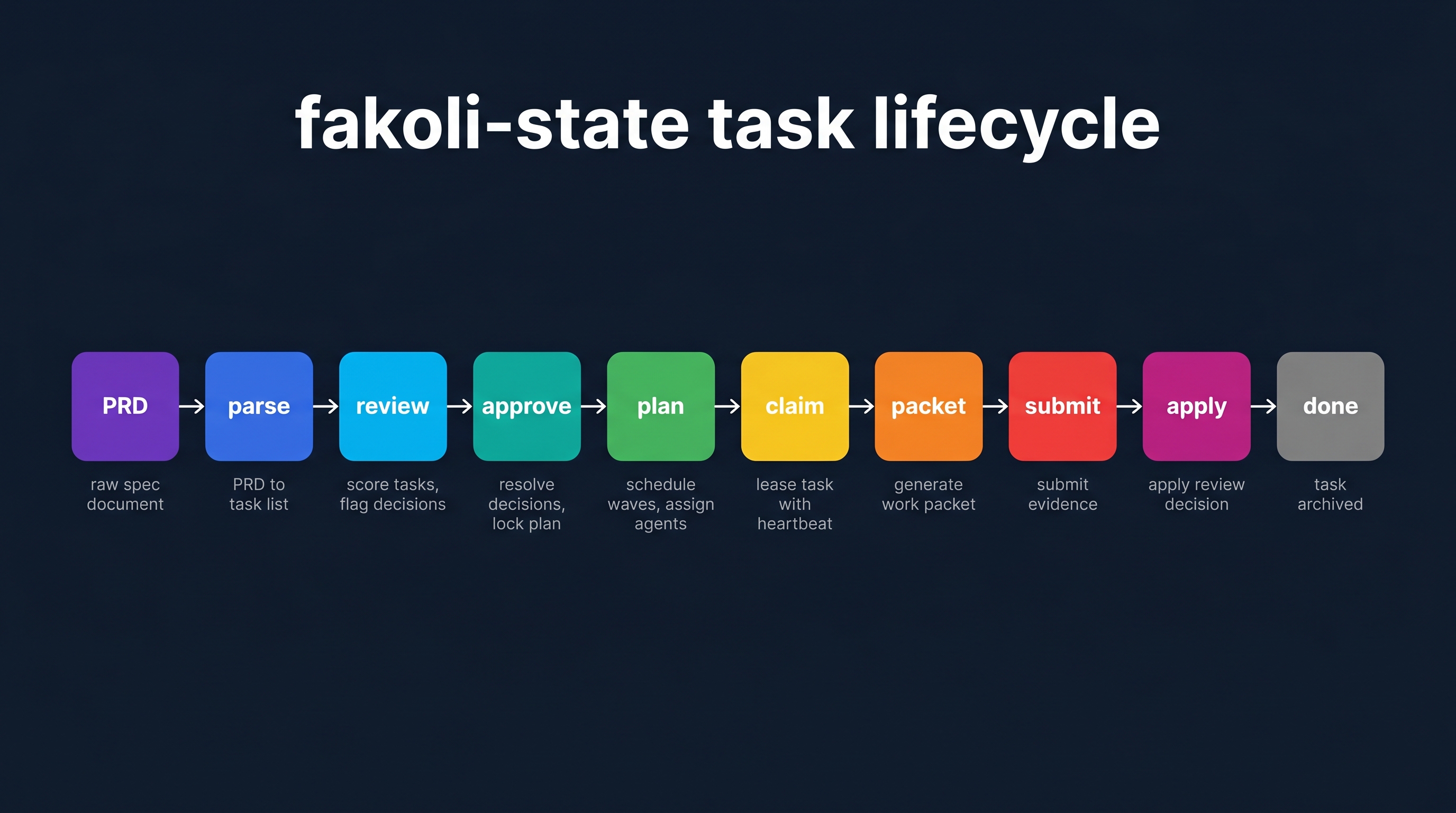
# 1. Scaffold per-project state
fakoli-state init --name "My Project"
# → creates .fakoli-state/{config.yaml, state.db, events.jsonl, packets/}
# 2. Write the PRD against the template
$EDITOR .fakoli-state/prd.md
# 3. Parse, review, approve — the state machine requires
# draft → reviewed → approved before tasks can be claimed
fakoli-state prd parse
# → Parsed PRD: 4 requirements, 12 tasks staged for review
fakoli-state prd review # draft → reviewed
fakoli-state prd review --approve # reviewed → approved
# 4. Generate features and tasks; score across six dimensions
fakoli-state plan
fakoli-state score
# → tabular output:
# TaskID Complexity Parallel CtxLoad Blast Review Agent
# T001 3 5 2 2 3 4
# T002 5 1 4 4 4 2
# T003 2 5 1 1 2 5
# ...
# 5. Pick the next ready task and claim it
fakoli-state next
# → T001 — "Wire orchestrator retry to DLQ" (ready, no conflicts)
fakoli-state claim T001
# → Claim C001 active; branch agent/t001-wire-orchestrator-retry created
# → lease_expires_at: 2026-04-24T15:32:00Z (60 min)
# 6. Get the work packet, do the work, submit evidence
fakoli-state packet T001
# → renders intent + acceptance criteria + scope + non-goals
# + dependencies completed + verification commands
# as markdown the agent can read directly
fakoli-state submit T001 \
--commands "pytest tests/test_retry.py" \
--files-changed src/orchestrator/retry.py
# 7. Apply the review verdict — promotes needs_review → accepted → done
fakoli-state apply T001 --approve
# → Task T001 applied; event task.applied recorded in events.jsonlA few things in that sequence are worth pulling apart, because each one was a design decision I’d happily defend.
Claims Have Heartbeats Because Markdown Doesn’t
The claim model is the part of the system I had to rebuild three times before it sat right.
The first version had claims as a flat row with claimed_by and a creation timestamp. Worked fine for one agent. Failed the first time an agent crashed mid-work, because the claim sat in the database forever with no way to know it was abandoned.
The second version added a lease — a fixed expiry timestamp set at claim time. A 60-minute lease meant abandoned claims got reclaimable after an hour. Better. But it created a new failure mode: an honest long-running task would lose its claim partway through, and a second agent could grab the same task while the first was still working.
The third version is what shipped. A claim has both lease_expires_at and last_heartbeat_at. Honest agents call fakoli-state renew T001 every five minutes to extend the heartbeat. The stale-claim sweep — which runs on every CLI and MCP operation, not in a background daemon — releases claims whose lease has expired and whose heartbeat hasn’t moved recently. Lease plus heartbeat lets me pick a short default expiry (60 minutes, configurable) while honest work keeps moving and crashed work gets reaped fast.
I rejected branch-name conventions (agent/t001-foo as the claim) and git-LFS-style file locks for the same reason: branches don’t expire, files don’t predict their own conflicts, and neither has a heartbeat. The agent/<task>-<slug> branch still gets created at claim time, but as a projection of the canonical claim, not as the claim itself. If you delete the branch, the database row still says you have the work.
Two other things are worth knowing about the claim object. It carries an expected_files list — the agent’s best guess at what it’ll touch. That doesn’t block edits outside the list (more on why in the hooks section), but it surfaces pre-claim conflict warnings: if T001 expects to touch src/orchestrator/retry.py and T015 is already claimed with the same expected file, fakoli-state claim T015 warns before proceeding. And the claim is held in SQLite, not in any one agent’s session memory — which means cross-runtime safety. A Claude Code session can claim a task and a Codex session can see the claim and refuse to grab it, because both runtimes are reading the same database.
Evidence Is Captured, Not Narrated
The other place the system enforces discipline is at the evidence boundary, and this is the one I’m proudest of.
The model is structured. The Evidence payload requires commands_run (every shell command the agent actually executed), files_changed (paths touched), output_excerpt (last N lines of test or build output), exit_codes (per-command), and an optional artifacts list (screenshots, logs, links). The sentinel validates the payload before a task can move to accepted. Free-form “tests passed” strings are rejected.
The trick is that the agent doesn’t supply the ground truth. The hook does.
capture-evidence.sh runs as a PostToolUse hook on the Bash tool. Every command the agent runs in the scope of an active claim gets recorded — the command, the exit code, the last lines of stdout and stderr. That recording lives in a per-claim evidence buffer. When the agent submits via fakoli-state submit T001, the agent cites what to include from the buffer. The hook supplied the truth; the agent supplied the curation.
This split matters because it closes the loop on the AI-slop problem. An agent that fabricates commands_run: ["pytest"] without having actually run pytest gets caught — the hook stream for its claim’s window shows no pytest invocation, and the sentinel cross-checks them. Lying takes more effort than telling the truth, and the lying gets logged.
I’ll admit a limitation here. The buffer captures what the Bash tool sees. An agent that has access to other tools — Edit, Write — has those captured by separate hooks (record-file-change.sh for file ops), but the abstraction isn’t as clean. If a future agent finds a tool I haven’t hooked, the evidence loop has a gap there. So far the gap hasn’t been exploitable in practice because the verification commands the sentinel runs are themselves Bash invocations, and those are captured.
Why Hooks Don’t Block
This is the design choice that surprises people the most when I explain it.
All four hooks in the plugin — detect-state.sh, check-claim.sh, record-file-change.sh, capture-evidence.sh — exit 0 regardless of internal failure. They don’t use set -e or set -u. They wrap CLI calls with || true. They must complete in under 200 milliseconds on hot events like PreToolUse and PostToolUse.
The version I almost shipped instead would have made check-claim.sh block: if an agent tried to edit a file outside its claimed scope, the PreToolUse hook would refuse the Edit tool call. I almost shipped this because it felt like enforcement. I didn’t ship it because of three things I learned in testing.
The agent routes around blocking hooks. A Claude Code agent that hits a blocking Edit refusal learns to call Bash("sed -i ...") instead. Hook coverage shrinks the moment agents start treating the hook as an adversary. The trust between the agent and the system degrades — and the agent isn’t doing anything wrong, it’s just trying to get the work done.
False positives kill the workflow. A task can legitimately need to touch a file it did not predict. The expected_files list is a hint, not a contract. A blocking hook turns “I should warn the human” into “I am breaking the session,” which is a worse failure mode than the one it was trying to prevent.
Hooks run in the user’s shell. A set -e script that hits an unexpected condition can silently kill PreToolUse for all tools, not just Edit. The blast radius of a hook bug is much larger than the blast radius of a missed warning.
So the right shape is warn-plus-log-plus-audit. The check-claim hook prints a one-line warning to stderr — “warning: editing src/foo.py outside active claim T012 scope” — and appends an event to events.jsonl. The human or the downstream sentinel decides whether the warning matters.
Non-blocking does not mean toothless, though. Discipline is layered. The hooks observe and warn. The state engine enforces invariants — claim_task refuses if the PRD is still draft or another active claim holds the task; Pydantic refuses malformed input at every boundary. The apply gate is the hard gate. No Evidence row means no transition to accepted. No Review row means no transition to done. The hook can be soft because the gate is hard.
Two Front Doors, One Engine
Every state operation has two front doors. A Typer-based CLI for humans and shell scripts (fakoli-state claim T012). A FastMCP stdio server exposing 22 tools for agents (claim_task(task_id="T012", actor="claude-session-abc")). Both delegate to the same state/ engine. Neither owns workflow logic.
CLI-only would have forced agents to shell out and parse stdout. Some can — Claude Code with Bash, Codex with its tool harness. Some can’t — Cursor has no shell. Shell-out also loses structured errors; the agent has to grep the CLI output for the error type instead of getting an exception object back.
MCP-only would have failed the other way. Humans hate MCP for debugging. Shell scripts hate MCP. Hooks are sh — they can’t speak MCP. fakoli-state status in a terminal during a session is faster than spinning up an MCP client, and that latency matters because debugging happens at the worst possible time.
REST or HTTP would have required a long-running process. Daemon problems: launchd integration, port collisions, “is it running” debugging, authentication. I get the agent-tool benefits via MCP stdio without any of that — the MCP server dies with the agent that spawned it.
The tradeoff I accepted is two surfaces to keep in sync. I mitigated by sharing the engine: both surfaces construct the same Backend, call the same ClaimManager.claim(), surface the same exceptions. If the engine layer is correct, both surfaces are correct. The principle from the positioning docs that drove this: MCP exposes capabilities; the plugin layer encodes operating discipline. The MCP tool claim_task does not decide when to claim, which specialist should execute, or what evidence is required — those decisions live in skills, agents, and hooks.
Six Dimensions, Not Story Points
Every task carries six scores on a 1-to-5 scale: complexity, parallelizability, context_load, blast_radius, review_risk, agent_suitability. Complexity at 4 or higher triggers an expand recommendation. Agent suitability drives routing between Opus, Sonnet, Haiku, or a local model.
Single-axis story points conflate three different things: “hard to think about,” “lots of files to touch,” and “scary to ship.” The conflation hides the actually interesting signal. A task can be low-complexity but high-blast-radius — renaming a public API. A task can be high-complexity but low-blast-radius — a tricky algorithm in one file. Routing needs both axes; story points give one.
Six is more cognitive load than one. I mitigated by making LLM-assisted scoring the default (score --use-llm). The deterministic fallback gives reasonable defaults from heuristics on the task description, so a project without an Anthropic API key still gets useful numbers. What I lost: comparability with existing sprint velocity charts. The audience isn’t running sprint retros.
What I’m Still Living With
I want to be honest about what isn’t solved.
Heartbeat discipline is on the agent. An agent that never calls renew will see its claim go stale at the lease deadline, even if the work is honest and ongoing. I deliberately did not automate this with a daemon — the daemon problem is real — but it means that the discipline of “renew while you work” has to be in the agent’s prompt or in the skill that wraps the work. Most of the time it is. When it isn’t, the system fails by reclaiming work that someone is still doing.
The Backend Protocol is half-built. The codebase has a Backend Protocol in state/backend.py with the seams a second implementation would need, but only SqliteBackend ships. Abstractions calcify against their only implementation. I’d rather refactor when a real user has a real reason — a team that wants Postgres, an embedded use case that wants pure JSON — than ship three half-tested backends to look more architectural.
Sync is polled, not pushed. The GitHub Issues sync provider runs on a watch loop with a polling interval, because webhook handling needs a public HTTP endpoint, HMAC verification, out-of-order delivery semantics, and an at-most-once contract. None of that is needed at the current single-user-laptop scale. The day someone runs sync on a server with public DNS, that calculus changes. Until then, polled is the right trade.
There’s no real dashboard. You can read the state.db with any SQLite browser. The fakoli-state CLI has status, list, show, and next for the common queries. But there’s no web UI. That’s a deliberate choice — the wedge is local-first and the dashboard would compete with Linear and Jira — but it means new users have a heavier learning curve than they would in a SaaS tool. Whether that’s the right trade for the wider audience or only the right trade for me is something I’ll find out as more people pick this up.
Durability Is the Precondition
The last post in this series is about what changes when the state, the workflow, and the crew are all working together. I’ll save the synthesis for that piece.
What I want to leave you with from this one is the principle that drove every choice above. Trust between you and an agentic system is built on the same thing trust between you and any other system is built on: things you wrote down stay written, things that should be locked are locked, and things claimed to have happened actually happened. Markdown will not give you any of those properties. A SQLite file with WAL and an event log and claim heartbeats and evidence captured by hooks will give you all four.
You can build a workflow without that foundation. People do. I did, for six months. It works until it doesn’t, and when it stops working you usually find out the way I did — three agents in parallel, three internally-consistent worldviews, none of which match the codebase, and no record of how any of them got there.
Build the state layer first. The workflow on top of it is much easier to trust.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/fakoli-plugins
This article discusses an open-source project. Star it, fork it, or open an issue.