Designing Multi-Region Infrastructure: Patterns That Scale
A taxonomy of region types, spec-driven provisioning, and phased orchestration for predictable multi-region expansion.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer. These patterns reflect general industry practices I’ve developed over my career, not proprietary details of any specific organization.
I’ve watched a multi-region rollout work perfectly in the primary region and silently break in the second one. Not loudly. Not with alarms. Quietly — the kind of failure where you only discover the problem when a regional failover is attempted and the “standby” region turns out to be running six months behind.
The gap wasn’t a networking misconfiguration or a broken Terraform module. It was a Region B that had never actually matched the spec for Region A. Two regions with the same name on the architecture diagram, two completely different operational realities. Nobody had noticed because nobody had compared them systematically.
That experience is where most of these patterns came from. Multi-region infrastructure sounds simple in theory: replicate your stack, set up DNS failover, done. In practice, it’s where good intentions meet harsh reality. Networking gets weird. Data replication introduces problems you didn’t know existed. Your deployment pipelines need to suddenly care about geography. Your cost model doubles. Your operational runbooks triple.
I’ve led multi-region initiatives at multiple points in my career, and every single time, I’ve been humbled by how much harder it is than the architecture diagram suggests. What follows are the patterns I keep reaching for because they actually work. Not a step-by-step guide — your constraints are different from mine — but the mental models that have kept me from making the same mistakes twice.
Stop Copying Your Primary Region Everywhere
This is the first mistake I see teams make, and it’s an expensive one.
The instinct is to make every region identical to your primary. Same services, same capacity, same everything. It feels safe. It feels symmetrical. It also costs a fortune and creates an operational burden that’ll crush your team.
I’ve found it much more useful to think in terms of a region types taxonomy:
Full regions get the works. Every service, full read-write capability, able to operate independently. These are your primary regions and your major failover targets. You might have two or three of these, max.
Lightweight regions are slimmer. Maybe they handle specific workloads, serve as regional points of presence, or run a subset of services. They don’t carry the full infrastructure footprint, and that’s by design.
Read-Only regions do exactly what the name says. They serve read traffic using data replicated from a primary. They’re simpler to operate because you sidestep the hardest distributed systems problems: consistency and conflict resolution. If you’re mostly trying to reduce latency for users in a distant geography, this is often all you need.
Why does this taxonomy matter? Because it drives every downstream decision. How much networking do you provision? What services get deployed? How much operational coverage do you need? A Full region and a Read-Only region have completely different answers to all of these questions. Encoding that distinction explicitly prevents the default behavior of over-provisioning everything everywhere.
The Region Artifact: Your Spec Before You Spend
The second pattern that’s saved me from chaos is what I call a Region Artifact. It’s a declarative specification that defines what a region needs before any infrastructure gets provisioned.
The idea is simple. Before standing up a new region, you write down what it actually requires. Here’s a partial example of what one looks like:
region:
name: us-west-2
type: full # full | lightweight | read-only
purpose: primary-failover
networking:
vpc_cidr: 10.20.0.0/16
connectivity:
- type: peering
target: us-east-1
- type: transit_gateway
target: eu-west-1
services:
deploy:
- api-gateway
- container-orchestration
- secrets-management
- monitoring
exclude:
- batch-processing # lightweight regions only
compliance:
data_residency: US
encryption_at_rest: required
audit_logging: requiredThis spec becomes the source of truth for everything downstream. Terraform modules read from it. CI/CD pipelines reference it. Monitoring configs derive from it. Instead of five teams independently guessing what to deploy, the Region Artifact gives everyone a shared picture.
The real benefit is predictability. When someone asks “what does it take to expand into a new region?” the answer isn’t a six-week discovery process where you ask every team what they need. It’s: “here’s the spec, here’s the cost estimate, here’s the timeline.” That kind of clarity is what turns multi-region from a scary project into a repeatable operation.
And it solves the silent drift problem I described at the top. When Region B was supposed to be a full-region failover but ended up half-provisioned, nobody caught it because there was no spec to compare against. The Region Artifact is that comparison baseline.
Four Phases, In Order
Standing up a new region isn’t a single terraform apply. It’s a sequence of dependent phases, and each one needs to finish before the next one starts. I’ve tried to shortcut this. It doesn’t end well.
Here’s what the phase dependency actually looks like in practice:
| Phase | Name | Gate Criteria | Blocks |
|---|---|---|---|
| 1 | Landing Zone | Security baselines pass, audit logging active | Everything |
| 2 | Network | VPC live, peering validated, DNS resolving | Phases 3–4 |
| 3 | Infrastructure Substrate | Monitoring active, secrets management up | Phase 4 |
| 4 | Workloads & Routing | Validation tests pass | Traffic shift |
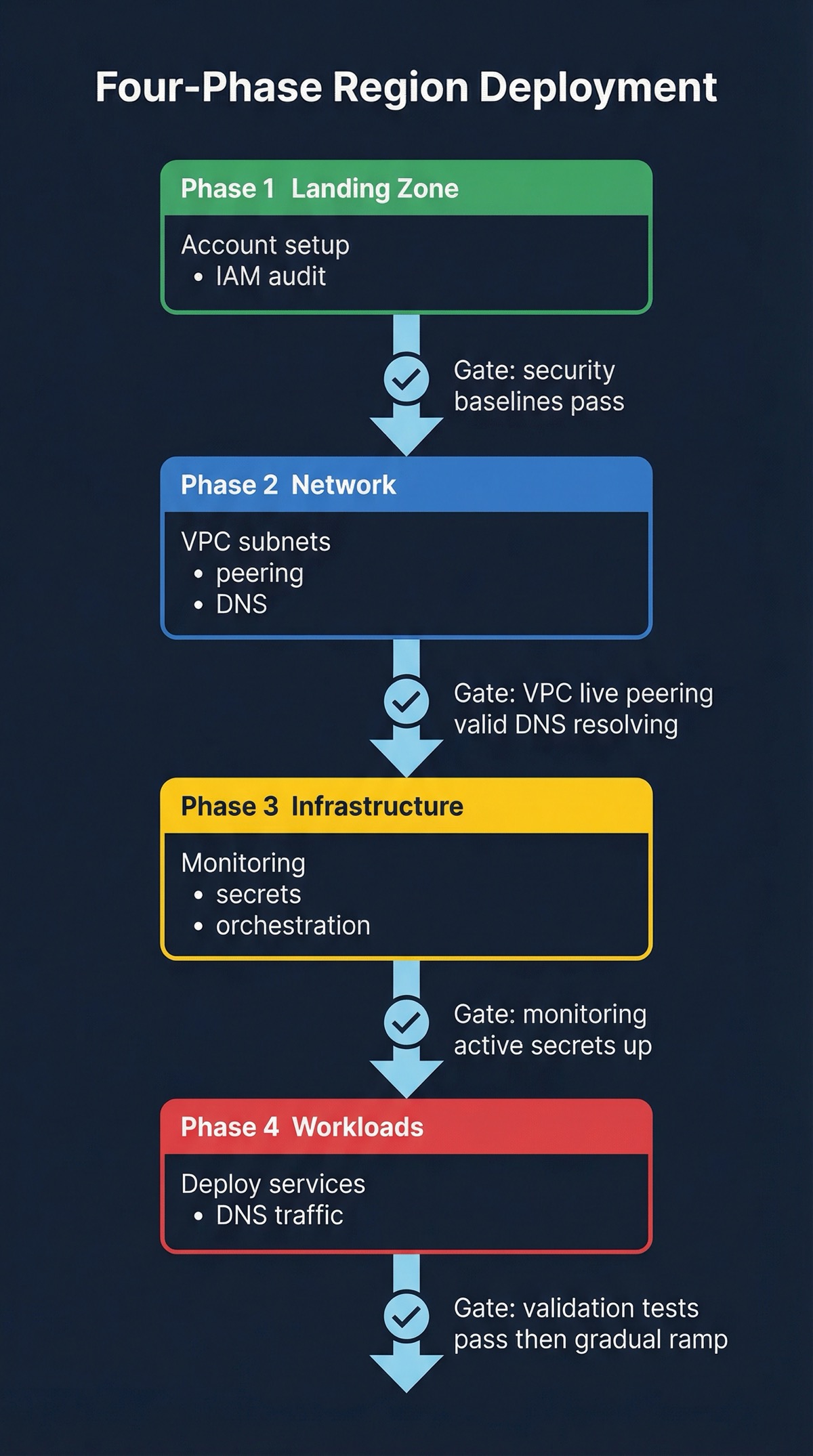
Land Before You Build
Foundation first. Account setup, IAM policies, security baselines, audit logging. Nothing else happens until this is solid.
Think of it as the “you must be this tall to ride” check. If the account doesn’t meet security and governance baselines, you stop here. I’ve seen teams try to skip ahead and deploy workloads into accounts that weren’t properly secured. The cleanup is always worse than the delay.
Network Is the Foundation
With a proper landing zone, you build the networking layer. VPC creation, subnet design, peering or connectivity back to existing regions, DNS, security groups. This is where the region type matters most. A Full region needs comprehensive connectivity; a Read-Only region can get away with something much simpler.
Don’t forget control plane connectivity. You need to manage this new region from your existing tools, and that plumbing needs to be in place before anything else goes live.
The Shared Services Layer Nobody Wants to Build Twice
This is the shared services layer that workloads depend on: container orchestration, monitoring, secrets management, service discovery, logging. All of it needs to be running before you deploy application code.
This phase is where golden-path solutions pay for themselves. If you’ve invested in standardized Terraform modules for your orchestration clusters, monitoring stacks, and CI/CD pipelines, standing up the substrate is just applying those modules with region-specific parameters. If you haven’t? This phase becomes a manual slog. And I promise you, “we’ll standardize later” becomes “we never standardized” faster than you’d think.
Traffic Follows Validation, Not the Other Way Around
Finally, you deploy your actual services and start routing traffic. Deploy according to the region type spec. Configure load balancing and DNS. Run validation tests.
Then the critical part: shift traffic gradually. Start with synthetic traffic. Move to a tiny percentage of real users. Validate everything. Ramp up slowly. I’ve seen teams flip from 0% to a significant percentage overnight and discover that their replication lag was worse than expected, their monitoring wasn’t catching errors in the new region, and their runbooks didn’t account for the new topology. Don’t be that team.
The Principles Behind the Patterns
These are the convictions that shaped every decision above. I’m not presenting them as bullets — bullets make principles feel like fortune cookies. Each one is something I had to learn from a mistake.
Make expansion boring. The goal is not cleverness. It’s repeatability. If standing up a new region requires heroic effort from your best engineers, your architecture isn’t ready for multi-region. You want the process to be so well-understood that a junior engineer could drive it with good documentation. Actually, that’s the test. If you can’t write documentation that lets someone else run the playbook successfully, the playbook isn’t ready yet.
Data is actually the hardest problem. Networking, compute, and deployment are all solvable with good automation. Data replication, consistency, and conflict resolution are where multi-region gets genuinely, deeply hard. I’ve spent more time on data strategy for multi-region than on everything else combined, and I’d do it again. Teams that underinvest here discover it the worst possible way — during an incident when the replication lag they didn’t know about becomes a data loss scenario.
Design for partial failure, not binary failure. In a multi-region setup, something is always partially broken. A region is degraded. A replication pipeline is lagging. A deployment is rolling out unevenly. Your architecture needs to handle these gracefully, not just the binary “region up or region down” scenario. The interesting failure modes are the partial ones. A fully-down region is obvious. A 40%-degraded region that passes health checks is dangerous.
Cost model every region type, before you commit. The taxonomy only works if you know what each type costs. A Full region costs dramatically more than a Read-Only one, and that difference needs to be visible and planned for. Surprises in your cloud bill at this scale are not the fun kind of surprises.
Cross-region observability is not optional. You need to see the state of all regions from one place. Per-region dashboards are great for debugging, but cross-region visibility is where you actually understand system health. When something is going wrong in one region because of a change in another, you need to be able to see that connection.
What’s Still Hard
I want to be honest about the limitations here. These patterns handle the operational complexity of multi-region well. They make expansion predictable. They prevent the most common mistakes.
What they don’t solve: the distributed systems problems at the data layer. Conflict resolution for writes that land in two regions simultaneously. Consistency models that work for your use cases. The fundamental tension between availability and consistency that no pattern can make disappear. I don’t have a clean framework for those problems, because I don’t think a clean framework exists. The best I’ve seen is teams that have thought them through carefully and made explicit, documented choices — not teams that found the right abstraction.
Multi-region isn’t a project with a finish line. It’s an operating model that evolves as your organization grows. The patterns here — region taxonomy, spec-driven provisioning, phased orchestration — are frameworks for making that evolution predictable instead of chaotic.
The architecture decisions matter. But it’s the operational discipline to execute them consistently, across every region, every time, that separates multi-region as a strategy from multi-region as a liability.
Co-authored with AI, based on the author's working sessions, dictations, and notes.