Intent Should Be Durable: The Missing Layer Between Agent SDKs and Production Systems
Agent SDKs give you tools and reasoning. They don't give you queues, checkpoints, or crash recovery. That gap is where your intent dies.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer.
I was three hours into a code migration when the agent hit an API rate limit and stopped. Not crashed. Not errored out. Just stopped, mid-task, waiting for me to notice. I didn’t notice. I’d closed the laptop and gone to dinner. When I came back, the terminal was sitting on a retry prompt like a dog waiting at the door. The agent had been capable of finishing the work. It just couldn’t survive my absence.
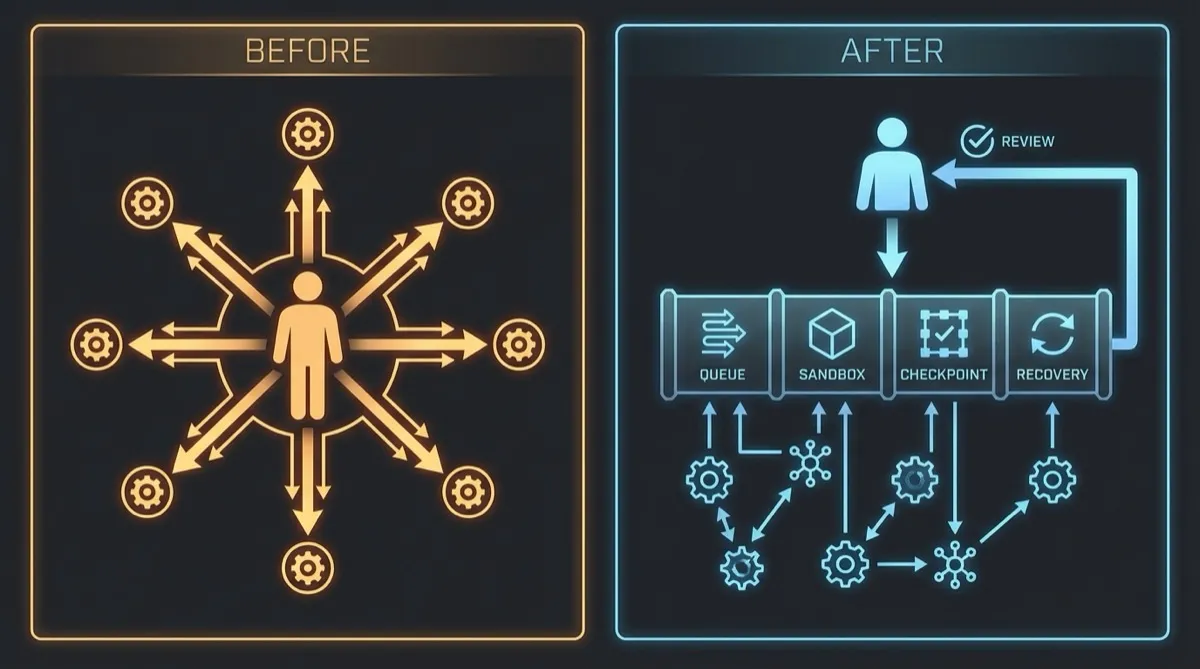
That moment crystallized something I’d been circling for months. The bottleneck in my agent workflows wasn’t intelligence. It wasn’t tool coverage. It wasn’t the model. It was me. I was the execution runtime. Every agent I ran needed me present — watching for failures, re-prompting after errors, restarting after crashes. Close the laptop, the work stops. My intent didn’t survive the walk to the kitchen.
The problem isn’t that agent SDKs are bad. They’re genuinely good. They give you tool use, reasoning, multi-turn conversation, structured output. What they don’t give you is the infrastructure to run that intelligence unsupervised. No queue. No checkpoint. No crash recovery. No dead letter triage. The SDK is the engine, but there’s no chassis. And without a chassis, the engine only runs while you’re holding it.
What Baara v1 Taught Me
The first version of Baara — named after the Mandinka word for work, for craft — was my attempt to fix the interface problem. Nineteen tools, six production dependencies, a vanilla JS frontend, direct execution. You could talk to it in natural language, and it would compose tools on the fly. It was genuinely useful. I described a task, the agent figured out which tools to call, and the work got done.
I was wrong about what I’d built. I thought I was building a better way to work with agents. What I’d actually built was a better interface to agents. The execution model was still synchronous. Direct execution meant the agent ran in my process, in my terminal, on my schedule. When a task failed at 2am, it sat there until I woke up and noticed. When the process crashed, the work was gone. No recovery. No checkpoint. Just a log entry and a fresh start.
The pattern that would eventually become v2 wasn’t designed at a whiteboard. It was discovered through repeated frustration. Every time I had to restart a long-running task from scratch because the process died, I’d think: the agent did twenty minutes of useful work and I just lost all of it. Every time I set up a cron job outside of Baara to trigger a task inside of Baara, I’d think: why am I the glue between the scheduler and the executor? The answer kept being the same. There was a missing layer between the agent SDK and anything resembling a production system. I just hadn’t named it yet.
The Durable Agentic Execution Pattern
Let me name it now. The pattern is four layers, and each one removes a specific dependency on the human.
Queue — removes timing dependency. Your intent survives scheduling. When you submit a task, it doesn’t need to execute right now, in your process, while you watch. It enters a queue and waits for capacity. Baara runs four named queues: transfer for standard work, timer for scheduled tasks, visibility for time-sensitive operations, and dlq for dead-lettered failures awaiting human triage. Each queue has configurable concurrency. The transfer queue handles ten concurrent executions. The dead letter queue processes one at a time, because triage shouldn’t race.
The queue is the most boring component and the most important one. Without it, every task requires your presence at submission time. With it, you can fire twenty tasks before bed and review outcomes in the morning. The queue turns “I need to be here” into “it’ll get to it.”
Sandbox — removes environment dependency. Your intent survives isolation. The agent doesn’t run in your shell, in your environment, with your permissions. It runs in a sandbox. Baara implements three behind a single ISandbox interface: native (direct SDK call in the host process, always available), WebAssembly (Extism plugin with memory and CPU limits), and Docker (container isolation, currently stubbed). The agent doesn’t know or care which sandbox it’s running in. The interface is the same. What changes is the blast radius when something goes wrong.
This is the tradeoff-first thinking that I keep coming back to. Native is fast and simple but has no isolation. Wasm gives you memory limits and CPU caps but adds complexity. Docker gives you full isolation but requires a container runtime. You pick based on what failure mode you’re most worried about. For personal tasks, native is fine. For anything touching external systems with credentials, you want boundaries. The pluggable interface means you don’t have to decide at architecture time. You decide at task time.
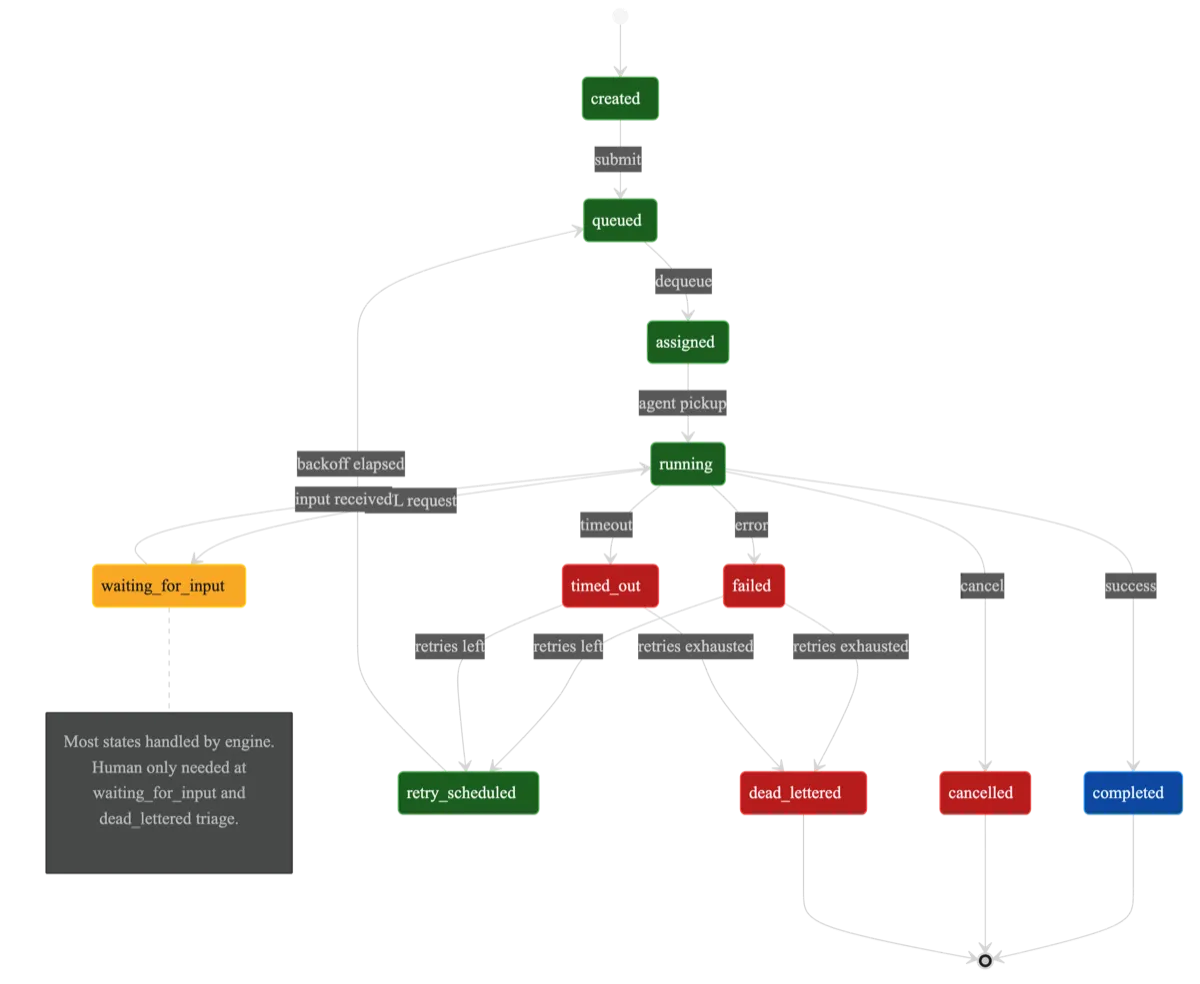
Checkpoint — removes continuity dependency. Your intent survives crashes. This is the hard one, and I’ll go deeper on it in the next section, but the core idea: after every N turns of conversation, the system snapshots the agent’s state — the full conversation history, any pending tool calls, and the agent’s working context. When a crash happens, recovery doesn’t mean starting over. It means loading the last checkpoint and continuing from turn N+1.
This is not event replay. That distinction matters, and I’ll explain why it matters shortly. For now: checkpointing gives you O(1) recovery. One database read. One context injection. Continue.
Recovery — removes failure dependency. Your intent survives errors. A health monitor watches running executions for signs of trouble — stuck processes, silent failures, timeouts. When it detects a problem, it doesn’t wait for you to notice. It retries with exponential backoff. When retries are exhausted, the execution moves to the dead letter queue for human triage. Not human execution. Human triage. The difference is everything. Triage means you look at a failure report and decide what to do. Execution means you’re the one running the task. One scales. The other doesn’t.

Together, these four layers form the chassis. The agent SDK is still the engine — it still does the reasoning, the tool use, the conversation. But now the engine has a queue to feed it work, a sandbox to contain it, checkpoints to preserve its progress, and recovery to handle its failures. The human moves from runtime to reviewer.
The Non-Determinism Insight
Let me be blunt about something. The traditional approach to durable execution doesn’t work for agents.
Systems like Temporal achieve durability through deterministic replay. They record every event — every function call, every side effect, every timer — and when a process crashes, they replay those events to reconstruct state. It’s elegant. It works beautifully for deterministic workflows where the same inputs always produce the same outputs.
LLM agents are not deterministic workflows. Send the same prompt twice and you’ll get different tool calls, different reasoning chains, different intermediate states. The model’s temperature, its attention patterns, even the order of tokens in its context window — all of it introduces variance. Replaying the events of an agent execution doesn’t give you the same state. It gives you a different execution that happens to start from the same place. Trying to replay an agent conversation is like trying to replay a human conversation word-for-word and expecting the same conclusion. The words might match. The thinking won’t.
I spent an embarrassing amount of time trying to make event replay work before I accepted this. I kept thinking: if I just capture enough state, if I just record the right events, I can reconstruct the execution. You can’t. Non-determinism isn’t a bug in the model. It’s a feature of how language models reason. Fighting it is fighting the medium.
The answer was right in front of me: stop trying to replay the execution. Checkpoint the conversation state instead. The conversation history is the state. It’s the accumulated context that the agent uses to decide what to do next. If you capture the conversation at turn 15 and the agent crashes at turn 17, you don’t need to replay turns 1 through 15. You load the conversation, tell the agent “you completed 15 turns, here’s where you were,” and it picks up from turn 16.
interface Checkpoint {
id: string;
executionId: string;
turnCount: number;
conversationHistory: ConversationMessage[];
pendingToolCalls: string[];
agentState: Record<string, unknown>;
timestamp: string;
}Recovery is a single database read — SELECT ... ORDER BY created_at DESC LIMIT 1 — followed by a context injection into the new execution. O(1). No replay log. No event store. No determinism requirement. The checkpoint captures what the agent knows, not what the agent did. That distinction is the entire insight.
There’s a cost I want to be honest about. Anything that happened between the last checkpoint and the crash is lost. If the agent completed two tool calls after checkpoint and then died, those calls happened but the agent won’t remember them. The agent needs to handle idempotency for work between checkpoints. For most tasks — file operations, API calls with deduplication keys, database writes with conflict resolution — this is manageable. For tasks with irreversible side effects and no idempotency, you checkpoint more frequently. The default in Baara is every five turns. You can set it to every turn if the work demands it. The tradeoff is write overhead versus recovery precision.
What Becomes Possible
When intent is durable, the way you work with agents changes fundamentally. Not incrementally. The whole interaction model shifts.
You schedule agents on cron. A task that checks deployment health every six hours doesn’t need you to remember to run it. It doesn’t need you to be awake. It runs, checkpoints its progress, handles its own failures, and routes its output to a thread you review when you’re ready. You submit tasks and walk away. Fire-and-forget isn’t negligence when the system has queues, retries, and dead letter triage. It’s the intended operating mode. The dead letter queue becomes your inbox — not for all agent work, just for the work that needs a human decision. Everything else resolves on its own.
The 27-tool MCP surface in Baara v2 is evidence that this pattern generalizes beyond simple automation. Task management, execution control, queue inspection, dead letter triage, template creation, project scoping, plugin discovery, skill execution — all of it accessible through three transports: stdio for Claude Code integration, HTTP for the web interface, and in-process for the chat system. The same tools, the same interface contract, regardless of how you’re talking to the system. The pattern doesn’t care about the surface area. It cares about the execution guarantees underneath.
What surprised me most is how it changed my relationship with failure. In v1, a failed task was an interruption. I had to stop what I was doing, diagnose the problem, restart the work. In v2, a failed task is a queue entry. It tried, it failed, it retried, and if it still couldn’t resolve, it landed in the dead letter queue with a full execution log. I look at it when I have time. I decide whether to retry with different parameters, adjust the task definition, or accept the failure. The agent’s failure is no longer my emergency. It’s my to-do item.
Durable Craft
In Mandinka, baara doesn’t distinguish between work and craft. The blacksmith’s work at the anvil is baara. The farmer’s work in the field is baara. There’s an embedded assumption that work is skilled, that it’s worth doing with care, that it persists. The basket the weaver makes outlasts the afternoon it was woven.
I keep thinking about that when I think about what makes agent execution real. The agent SDK gave us the skill — the reasoning, the tool use, the ability to break problems into steps. What it didn’t give us is the persistence. The craft that outlasts the session. Queue, sandbox, checkpoint, recover. Four layers, each one making the work a little more durable, a little less dependent on the person who started it.
The execution engine pattern is the missing layer between agent SDKs and production agent systems. That’s the claim, and I’ll back it up with code in Part 2. But the principle underneath it is simpler than the architecture: scaling your impact with AI agents means making your intent survive your absence. Every dependency you remove between “I want this done” and “it got done” is leverage. The queue removes timing. The sandbox removes environment. The checkpoint removes continuity. The recovery removes failure. What’s left is intent — durable, patient, waiting for capacity, surviving crashes, landing results in your inbox. That’s baara. Work that persists.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/baara-next
This article discusses an open-source project. Star it, fork it, or open an issue.