Why I Rebuilt My AI Assistant From Scratch (And What the Analysis Told Me)
How a structured competitive analysis of my own code convinced me that a clean-room rewrite was the right call, and what I learned building Nexus.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer.
I have a rule about rewrites: don’t. Almost every time someone says “let’s rewrite this from scratch,” they’re underestimating how much institutional knowledge lives in the ugly code they want to throw away. I’ve watched teams spend six months rebuilding something that already worked, only to end up with a shinier version of the same problems.
So when I decided to rewrite my personal AI assistant from scratch, I wanted to make sure I wasn’t falling into that trap. I did something I’d never done before for a personal project: I ran a formal competitive analysis on my own code.
The Problem With What I Had
I’d been running a personal AI assistant for a while. It worked. Sort of. The core execution loop was a single function that had grown to over three thousand lines. Adding a new AI provider meant touching six files. The error handling was a patchwork of try-catch blocks that swallowed failures in ways I couldn’t predict. And the test coverage was… aspirational.
The thing is, it still worked. I could chat with it, it responded, it did useful things. The classic trap. Functional enough to justify keeping, broken enough to resist improvement.
I kept running into the same wall: every time I wanted to add something (a new provider, a new channel, a new tool), the change rippled across the codebase in ways that surprised me. That’s the signal. When small changes require large understanding, the architecture has outgrown its design.
Analysis Before Architecture
Instead of just starting over and hoping for the better, I sat down and ran a structured analysis. Multiple passes, scored criteria, the kind of rigor I’d bring to evaluating a vendor product at work.
I looked at five dimensions: architecture quality, security posture, test coverage, developer experience, and extensibility. For each one, I documented what existed, what was missing, and what it would cost to fix in place versus rebuild.
The security review was the most sobering. No input validation on WebSocket frames. No credential encryption. No SSRF protection on the web fetch tool. No prompt injection detection. These aren’t things you can bolt on after the fact. Security architecture is foundational. When it’s missing from the beginning, retrofitting it means touching everything.
The scoring wasn’t even close. The existing system scored below three out of five on every dimension. A clean design, informed by everything I’d learned from the first attempt, scored above four and a half. The analysis didn’t just justify the rewrite — it actually gave me a blueprint for what to build. I stopped asking “should I rewrite this?” and started asking “what exactly am I building?”
What I Actually Built
Nexus is a self-hosted AI gateway. It connects to multiple AI providers through a unified interface, persists conversations in SQLite, and serves a web UI. It also bridges to Telegram and Discord, so I can interact with it from my phone without opening a browser.
That description sounds simple. The architecture underneath it is where the interesting decisions live.
Six packages, strict boundaries. The monorepo has six core packages: core (persistence, security, events), agent (execution loop, providers, tools), gateway (HTTP and WebSocket server), CLI, plugins, and UI. Each package has explicit dependencies. The agent package never imports from gateway. The CLI never touches the database directly. These boundaries sound obvious, but they’re exactly what the previous version lacked. When everything can reach everything, nothing is maintainable.
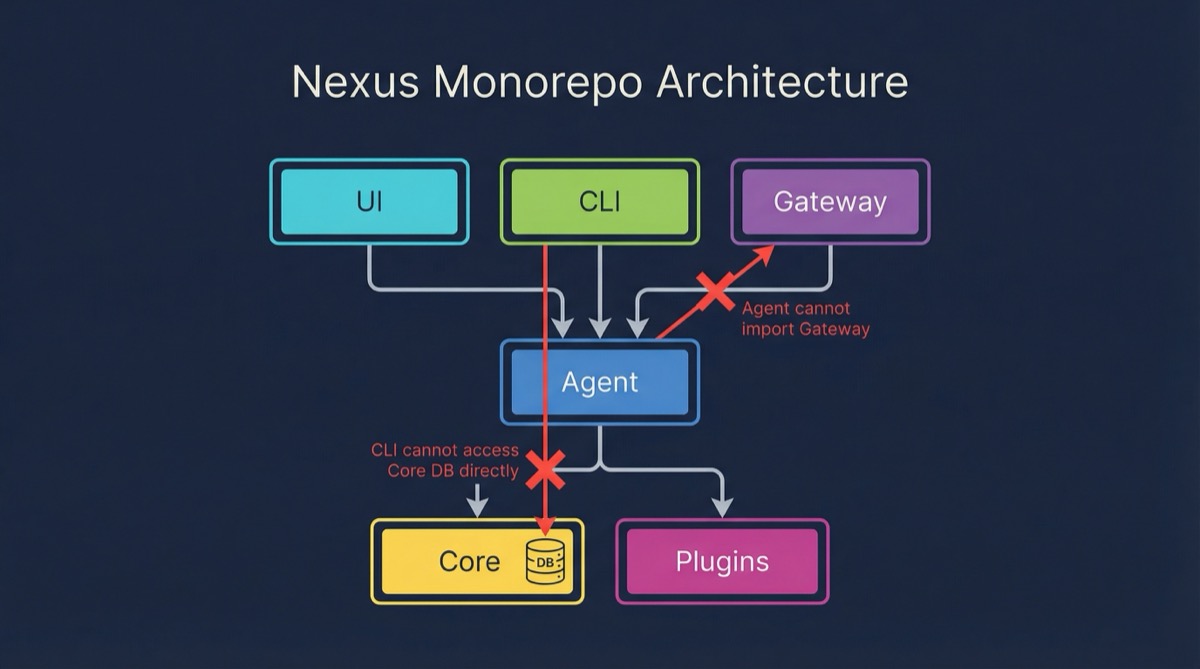
The execution loop is under a hundred lines. That three-thousand-line function? Its replacement is a clean loop: receive message, build context, call provider, handle tool use, persist result, stream response. Multi-turn tool calling, automatic context compaction when approaching limits, and streaming support all fit in that loop because the complexity lives in the right places, not piled into a single function.
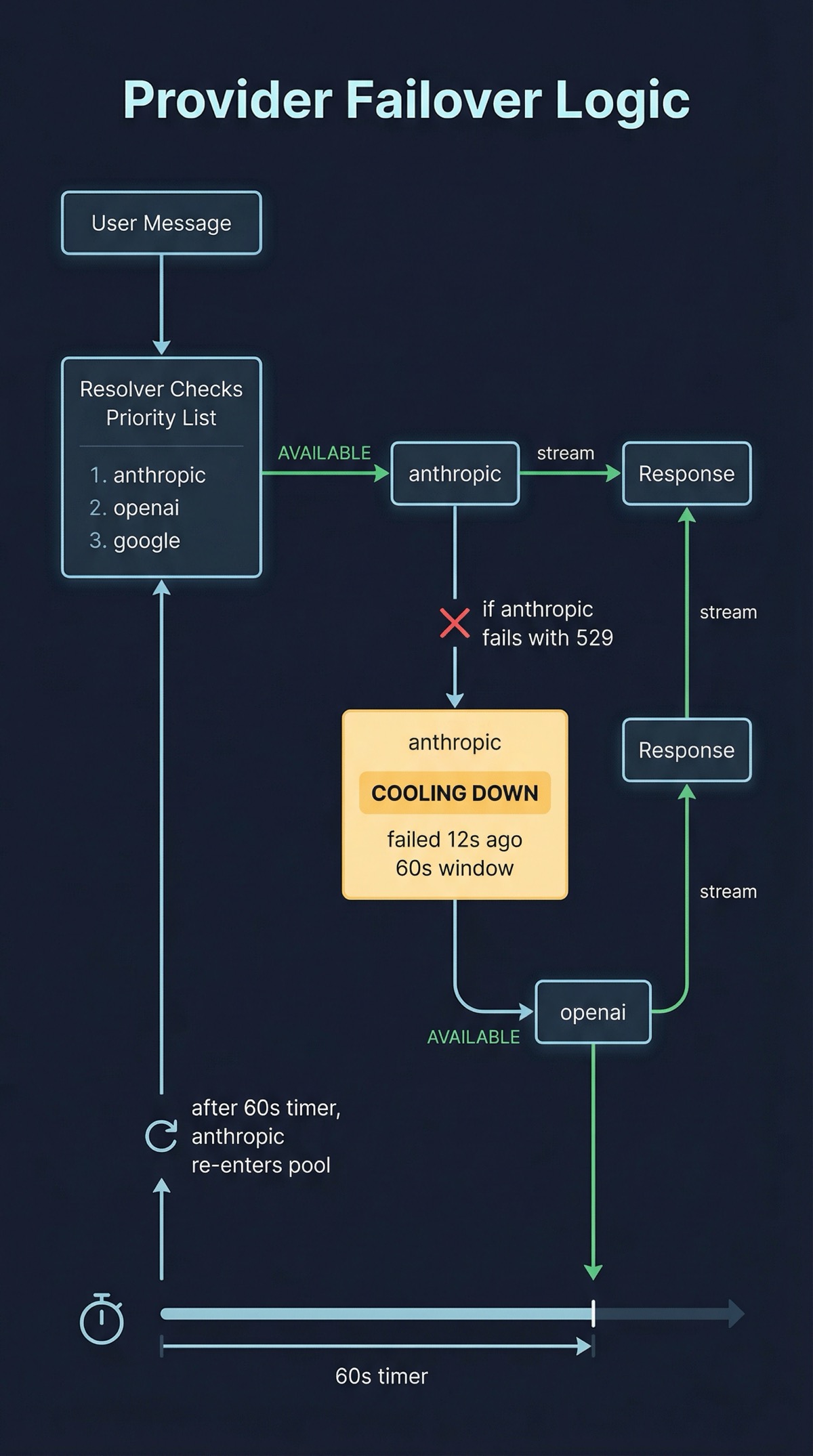
Seven providers, one interface. Anthropic, OpenAI, Google, Groq, DeepSeek, Ollama, and OpenRouter all implement the same interface: stream() returns an async generator, complete() returns a response. Adding a new provider means implementing two methods. The resolver builds a failover chain automatically. If the preferred provider fails, it tries the next one with a sixty-second cooldown on the failed provider. I don’t think about provider reliability anymore. The system handles it.
Here’s what the failover actually looks like in practice. Say I send a message and my preferred provider is Anthropic:
→ User sends message
→ Resolver checks provider priority: [anthropic, openai, google]
→ Anthropic: available (last failure: none)
→ stream() called → tokens flow back → done
// Later, Anthropic returns a 529 (overloaded):
→ User sends message
→ Resolver checks provider priority: [anthropic, openai, google]
→ Anthropic: cooling down (failed 12s ago, cooldown: 60s)
→ OpenAI: available
→ stream() called → tokens flow back → done
→ After 60s, Anthropic re-enters the pool automaticallyI don’t decide which provider serves a given request. The resolver does. I just rank them in order of preference and set the cooldown window. The operational result: I haven’t manually switched providers in months.
Security from day one. This is the part I’m most deliberate about. Prompt injection detection with sixteen regex patterns. SSRF protection on web fetch. Path traversal guards on filesystem tools. Encrypted credential storage with a master key. Rate limiting per client. Content boundary wrapping on tool output. Every WebSocket frame is validated with Zod before processing. None of this was in the original. All of it should have been.
The Channel Problem
Here’s something I didn’t expect to care about: I wanted to talk to my assistant from places other than a browser tab.
Telegram was the first adapter. Long polling, MarkdownV2 escaping (which is its own special kind of pain), message splitting for responses over four thousand characters. Each user gets their own session, so conversations don’t bleed across contexts.
Discord came next. Gateway WebSocket connection with the heartbeat and resume protocol that Discord requires. Each channel gets its own session. The bot responds to mentions and DMs only, which keeps it from being noisy in shared servers.
Both adapters use a device pairing system for security. When a new user messages the bot, they go through a pairing flow. Paired device tokens are stored in the database. Three policies: require explicit approval, accept all, or deny all. The default is pairing, because “accept all” on a publicly accessible bot is how you get someone else’s API bill.
What I Learned About Development Velocity
I built Nexus across five structured sprints in under two weeks. The test count went from zero to over a thousand. The reason that was possible isn’t some magic productivity trick. It’s that the analysis phase eliminated the wrong turns.
When you know what you’re building before you start, you don’t waste days going down dead ends. When the architecture is clean, tests are easy to write because the units are small and the boundaries are clear. When security is designed in from the start, you don’t discover at the end that your WebSocket handler needs a complete rework.
The analysis took a day. It saved at least a week of wasted iteration.
Federation Is a Bet I’m Not Ready to Evaluate Yet
The most forward-looking thing in Nexus is gateway-to-gateway federation. Two Nexus instances can connect to each other, exchange messages, and share sessions. The protocol uses typed frames validated with Zod: handshake, acknowledgment, message, session, stream. Auto-reconnect with message queuing for offline periods.
I’m not sure yet whether this is genuinely useful or just architecturally interesting. The idea is that personal AI should be distributed. Your work assistant and your home assistant shouldn’t be the same instance, but they should be able to communicate. Whether that matters in practice is something I’ll find out by using it.
I’m including it here because I think it’s worth being honest about: not every feature in a project earns its keep. Some are bets. Federation is a bet. I’ll know in six months whether it was a good one.
Self-Hosting Is a Line I Draw Deliberately
Let me be blunt about something. There’s a version of this project that’s a SaaS product. Multi-tenant, subscription model, managed infrastructure. I built the opposite on purpose.
Your AI conversations are some of the most personal data you generate. The questions you ask, the problems you’re working through, the half-formed ideas you’re testing. I don’t want that data on someone else’s server. I don’t want it training someone else’s model. I don’t want to wonder what happens to it when the company pivots or gets acquired.
Let me be precise about what “self-hosted” means here, because I’ve gotten questions about this. Nexus stores your conversations, configuration, and encrypted credentials in a SQLite database on your machine. Nothing phones home. No telemetry. No cloud sync. Your data stays on your hardware.
But it’s not an air-gapped system. When you send a message, Nexus calls the AI provider’s API — Anthropic, OpenAI, Google, whoever your resolver selects. Those prompts leave your machine. What Nexus controls is the storage and routing: your conversation history lives locally, your API keys are encrypted locally, the failover logic runs locally, and no third party ever sees the full conversation context. The providers see individual requests, not your archive.
That’s a deliberate line. I’m comfortable sending a prompt to an API. I’m not comfortable sending my entire conversation history to someone else’s database. Nexus lets me draw that distinction. That’s the choice, and it’s one I’d make again.
The Rewrite Lesson
I still think most rewrites are a mistake. But the ones that work share a pattern: they’re preceded by honest analysis, they’re informed by real operational experience with the thing being replaced, and they have clear architectural goals that can’t be achieved incrementally.
If I’d just started coding on day one, I would have built a slightly better version of the same mess. The analysis is what made the difference. It forced me to articulate what was actually wrong, not just what felt wrong. And it gave me a scorecard I could check my design against as I built.
The best infrastructure decisions I’ve made in my career all follow the same shape: understand the problem rigorously, make the tradeoffs explicit, and then build with conviction. Nexus reminded me that the same discipline works at every scale, from hyperscale cloud networks down to a personal side project.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/nexus
This article discusses an open-source project. Star it, fork it, or open an issue.