Teaching AI Agents to Work Like a Team (Not a Crowd)
What I learned building specialized agent archetypes that coordinate through file ownership, wave execution, and structured handoffs.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer.
The first time I ran five AI agents simultaneously on the same codebase, they stepped on each other’s work within thirty seconds. Agent A rewrote a file that Agent B was in the middle of editing. Agent C deleted a function that Agent D depended on. Agent E validated the codebase and found everything broken because the other four were still mid-flight.
It was a mess. A fast, impressively parallel, completely useless mess.
That experience taught me something I should have known from twenty years of building infrastructure with human teams: parallelism without coordination is just chaos with better hardware. And the coordination problem for AI agents is fundamentally the same problem I’ve been solving for engineering teams my entire career.
The Crew Hypothesis
The insight behind fakoli-crew is borrowed directly from how high-functioning engineering teams operate. You don’t have five generalists all working on the same files. You have specialists: an architect who designs the interface, a builder who implements it, an integrator who wires it into the existing system, a technical writer who documents it, and a QA engineer who validates everything before it ships.
Each person owns their domain. They communicate through artifacts, not constant conversation. The architect produces a design doc. The builder reads it and produces code. The integrator reads the code and connects it to the system. The writer reads the connected system and documents it. QA reads everything and produces a verdict.
That’s exactly what fakoli-crew does, except the team members are AI agents.
Eight Agents, Eight Roles
I built eight agent archetypes, each with a specific personality, a constrained set of tools, and clear rules about what they can and can’t modify.
Guido is the Python architect. Named after Guido van Rossum, obviously. This agent thinks in Protocols over abstract base classes, frozen dataclasses, snake_case everything, and the Zen of Python. It reads your code and tells you what’s Pythonic and what isn’t, with severity levels from “must fix” to “nit.” When I need an interface designed, guido does it. When I’m unsure about a naming convention, guido has opinions.
Critic is the code reviewer. Read-only tools. No Write, no Edit. It cannot modify your code even if it wanted to. This constraint is deliberate. A reviewer who can also fix things will start fixing things instead of thinking about them. Critic reads every file in scope before making a single comment, then produces a structured report with a binary pass/fail verdict.
Scout is the researcher. Web search, web fetch, file reading. When I’m integrating with a new API and need to understand the endpoints, rate limits, authentication scheme, and pricing before writing a single line of code, scout produces a structured reference document. It flags deprecated endpoints, notes undocumented behavior, and writes real code examples using httpx.
Smith is the plugin engineer. It knows the Claude Code plugin specification inside and out: the manifest schema, the hook wrapper format, the path resolution rules, the subtle gotchas (never add $schema to plugin.json, use allowed-tools not allowed_tools, never use set -e in hook scripts). When I need plugin infrastructure work, smith handles it.
Welder is the integration specialist. Its job is the hardest and the most thankless: take new code that other agents wrote and wire it into the existing system without breaking anything. Welder reads everything before changing anything. It uses facade patterns for delegation, re-exports for renamed modules, and compatibility shims when interfaces change. It’s the agent that prevents refactors from becoming regressions.
Herald writes documentation. It writes for strangers, not for the person who just built the thing. Active voice, present tense, no filler words. It produces READMEs that start with a concrete value proposition, include a copy-paste installation block, and assume the reader has never heard of the project.
Keeper maintains infrastructure: CI workflows, CLAUDE.md files, contributor docs, registry indices. Surgical edits, never wholesale rewrites. It checks that README counts match the registry, that CI paths resolve, and that the contributor checklist reflects reality.
Sentinel validates everything. Like critic, it has no write access. Unlike critic, it runs tests, checks version sync across manifest files, validates agent frontmatter, runs linters, and produces a binary scorecard. Every line is PASS or FAIL with exact error output. No hedging. No “looks mostly fine.”
The File Ownership Model
Here’s the thing that actually makes parallel execution work: one file, one primary owner per session. No exceptions for concurrent waves.
When guido creates a new Python module, guido owns that file. When welder integrates it, welder owns the wiring files. When herald documents it, herald owns the README. At no point do two agents write to the same file.
This isn’t a suggestion. It’s a hard rule. The ownership table is explicit:
New Python source? Guido. Existing Python source? Welder. Plugin manifest? Smith. README? Herald. CI workflows? Keeper. Tests? Guido writes them, sentinel reads them.
When a secondary agent needs changes in a file it doesn’t own, it writes the requested changes to its status file. The primary owner reads the status file and incorporates them. It’s pull-based coordination instead of push-based collision.
This is the same pattern I use with human teams. You don’t have two engineers editing the same Terraform module simultaneously. You have one engineer who owns the module and another who submits a request through a review process. The overhead is tiny compared to the cost of merge conflicts and broken state.
Wave Execution
The agents run in waves, not all at once. Five waves for a full project:
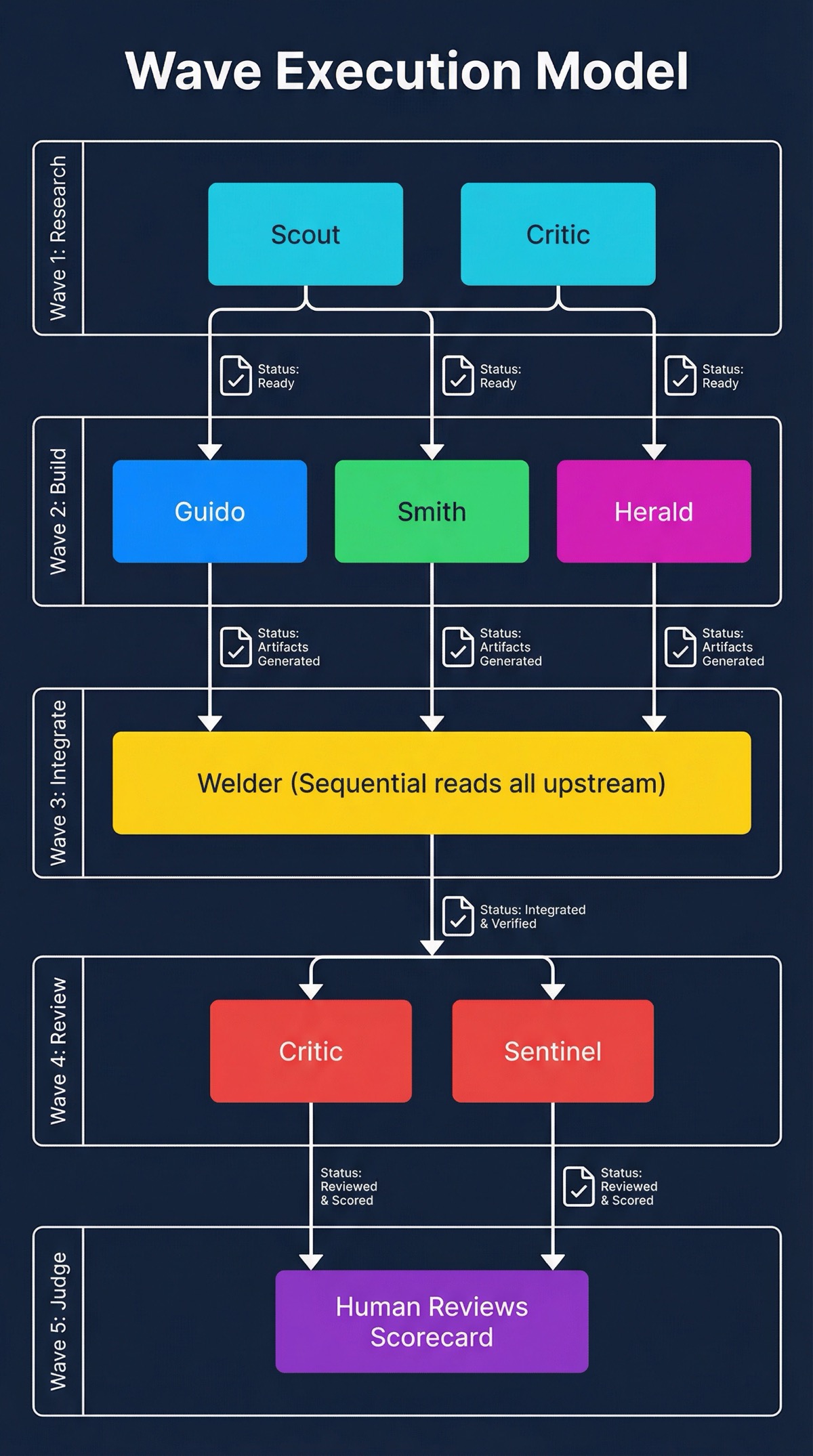
Wave 1: Research. Scout and critic run in parallel. Scout gathers external information. Critic reviews existing code. No changes to the codebase. Both produce status files documenting what they found.
Wave 2: Build. Guido, smith, and herald run in parallel. Each reads the Wave 1 status files first, then creates new artifacts within their ownership boundaries. Guido writes the code. Smith writes the plugin infrastructure. Herald writes the docs. They don’t need to coordinate in real time because they’re working on different files.
Wave 3: Integrate. Welder runs alone. This wave is sequential because integration touches everything. Welder reads every upstream status file, understands what was built and why, then wires it all together. Facade patterns, import rewiring, compatibility shims. The boring, critical work that prevents the project from being a pile of unconnected pieces.
Wave 4: Review. Critic and sentinel run in parallel. Neither makes changes. Critic reviews code quality. Sentinel runs the full validation suite. Both produce structured reports.
Wave 5: Judge. The human reads the scorecard and decides: ship it, or dispatch fixes back to the appropriate agent.
For small changes, the waves collapse. A one-file fix might be three waves: read, change, verify. The pattern scales down gracefully because the principle (separate research from building from integration from validation) holds at every size.
A Handoff In Practice
Let me make this concrete. Here’s what actually happens when I add a new plugin to the marketplace — say I’m wrapping a weather API.
Wave 1 kicks off. Scout researches the target API. When it finishes, its status file looks like this:
agent: scout
wave: 1
status: complete
findings:
- endpoint: api.openweathermap.org/data/3.0/onecall
auth: API key via query parameter
rate_limit: 1000 calls/day (free tier)
gotchas:
- "3.0 requires paid subscription; 2.5 is free but deprecated"
- "Units parameter defaults to Kelvin, not Celsius"
- recommendation: "Use 2.5 for free tier, design for 3.0 upgrade path"
next_agent_notes: >
Smith: use env var for API key, not hardcoded.
Guido: handle unit conversion in the interface layer.Simultaneously, Critic reviews the existing plugin loader and produces its own status file:
agent: critic
wave: 1
status: complete
verdict: PASS (with notes)
findings:
- file: src/plugins/loader.ts
severity: info
note: "Plugin registry uses synchronous fs reads — won't break, but
worth noting for future async migration."
- file: src/plugins/types.ts
severity: warning
note: "PluginManifest type lacks optional rateLimit field.
New plugin needs this if it enforces call limits."
next_agent_notes: >
Welder: check if manifest type needs extending before integration.
Smith: add rateLimit to manifest schema if weather plugin uses it.Wave 2 reads both files. Guido sees Scout’s note about unit conversion and designs the interface with a units parameter that defaults to Celsius. Smith sees Scout’s note about env vars and Critic’s note about the manifest type, so it extends the schema and uses process.env.WEATHER_API_KEY. Herald starts writing the README based on Scout’s API findings — the rate limits, the authentication scheme, the gotchas — without waiting for a single line of implementation code.
None of them talked to each other. They read artifacts. Pull-based coordination.
Wave 3: Welder reads every status file from Waves 1 and 2, sees that Smith extended the manifest type, wires the new plugin into the loader’s registry, and adds the rate limit middleware. One agent, touching only the integration files.
Wave 4: Critic re-reviews the entire changeset. Sentinel runs the test suite, validates the manifest against the schema, checks that the README’s feature list matches the actual tool count. Both produce structured reports — and here’s the part that matters: Sentinel’s report is a binary scorecard. No “looks mostly fine.” Every line is PASS or FAIL:
manifest_schema: PASS
tool_count_matches: PASS
readme_sync: PASS
test_suite: PASS (47/47)
version_consistency: FAIL — plugin.json says 1.0.0, package.json says 0.9.0That version mismatch gets dispatched back to Smith in Wave 5. The human (me) reads the scorecard, sees one FAIL, and sends it to the right agent. Smith fixes the version. Sentinel re-validates. Ship it.
The whole exchange took maybe six minutes. The important thing isn’t speed — it’s that at no point did two agents touch the same file, and every handoff left a paper trail I can audit.
What I Actually Use This For
I use fakoli-crew most heavily when working on the plugin marketplace itself. The irony isn’t lost on me: the plugin that manages plugins is maintained by agents specialized in plugin work. (Yes, I hear it. It’s turtles all the way down.)
A typical workflow: I want to add a new plugin to the marketplace. Scout researches the API or tool the plugin will wrap. Guido designs the Python interfaces. Smith handles the manifest and hook infrastructure. Welder wires it into the existing plugin loader. Herald updates the README and marketplace listing. Sentinel validates the whole thing. Keeper updates the registry index and CLAUDE.md.
Seven agents, five waves, one coherent result. The alternative is me doing all seven of those roles sequentially, context-switching between architecture, implementation, integration, documentation, and validation. That context-switching is where mistakes hide.
The other common use case is code quality audits. Critic and sentinel run in parallel, critic looking at code quality and sentinel looking at structural compliance. Together they produce a comprehensive view that neither would catch alone. Critic finds the subtle race condition. Sentinel finds the version mismatch in the manifest. Both matter.
What Doesn’t Work Yet
I want to be honest about the limitations.
Agent communication through status files works, but it’s coarse. The status file format captures what was done, what was decided, and what the next agent should know. It doesn’t capture the reasoning behind micro-decisions, the “I considered three approaches and chose this one because…” context that a human developer would share in a PR description. I’m still figuring out how much of that reasoning agents can usefully communicate to each other.
The file ownership model is strict by design, but it occasionally creates friction. When a fix requires changes to both the source code and the test file, and guido owns both, that’s fine. But when the fix spans guido’s domain and welder’s domain, the coordination overhead of status file handoffs starts to feel heavy for small changes.
And the wave model assumes the work can be cleanly decomposed into research, build, integrate, review. Most work can. But occasionally a task is deeply iterative: build a little, test, adjust, build more. The wave model handles that by running more waves, but each wave has startup overhead that makes tight iteration loops slower than they’d be with a single agent.
The Bigger Pattern
What I keep coming back to is that the problems of multi-agent coordination are the same problems of multi-human coordination. File ownership is code ownership. Wave execution is sprint planning. Status files are standups. The sentinel scorecard is a release checklist.
None of these ideas are new. They’re just applied in a context where the “team members” happen to be AI agents that can run in parallel and never get tired. The discipline that makes human teams effective, clear roles, explicit ownership, structured handoffs, quality gates, is the same discipline that makes agent teams effective.
I’ve been managing engineering teams for a long time. The lesson that keeps reinforcing itself is that coordination is the hard part. Execution is easy if you know what to build and who builds which piece. That’s true whether the builders are people or agents.
fakoli-crew is my attempt to encode that lesson into reusable infrastructure. Eight agents, five waves, one ownership table, and the hard-earned conviction that parallel work without coordination is just a faster way to make a mess.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/fakoli-plugins
This article discusses an open-source project. Star it, fork it, or open an issue.