
The Fakoli Style: An Operating Model for Building With Agents
Three plugins, four invariants, one principle. What I built isn't a toolkit — it's an operating model for serious development with AI coding agents.

Sekou M. Doumbouya
Listen to this article
The views expressed here are my own and do not represent those of any current or former employer.
Last month I shipped a non-trivial feature without typing a single line of code. I authored a PRD against a template. I ran fakoli-state prd parse and reviewed the parsed tasks. I ran fakoli-state plan and let the planner agent draft the work. I approved the plan. I ran flow:execute and walked away.
When I came back, two waves of work were done. Guido had built the new module. Welder had wired it into the existing system. Critic had caught two bugs. The fix cycle had run automatically. Sentinel had validated the evidence. The branch was waiting for me to merge.
The thing I did — the only thing I did — was decide what was worth building, write down what “done” meant, and decide whether the evidence at the end matched the criteria at the start. The part in the middle, the part that used to be my work, was the part the agents and the orchestration handled. I didn’t supervise the agents. I supervised the boundaries — the spec coming in and the verdict going out.
That’s the shift, and it’s the reason I built three plugins over the last year. For a long time I described them the way you’d describe any toolkit. Fakoli-crew is the specialists. Fakoli-flow is the orchestration. Fakoli-state is the durable record. Three pieces. Compose them. Done.
That description was true and it was useless. It told you what was in the box. It didn’t tell you what you were getting.
What you’re actually getting — and what I only saw clearly after fakoli-state shipped — is an operating model. The plugins are the implementation. The model is the part that survives if I rip out every line of code tomorrow and rebuild it in a different language.
I want to spend this last piece in the series describing that model, because I think it’s the most transferable thing I’ve produced. Whether you adopt the Fakoli plugins or not, the four invariants underneath them are choices anyone building seriously with AI coding agents has to make. Most people are making them by accident. I’m proposing you make them on purpose.
What Changed in How I Build
A year ago I built features by typing into a Claude Code session and approving each step. I knew the codebase. I made the decisions. The agent typed faster than I could, and that was the value.
That’s the shift. It’s not “AI did the work.” It’s “I changed jobs.” I used to be the person typing the code. Now I’m the person designing the work and judging the work, with the part in the middle delegated to a system I trust because I built the discipline into it.
This piece is about that discipline.
Four Invariants
I’m going to name four things that have to be true for the model to hold, and then explain why each one is non-negotiable. If you remove any of them, the model degrades back to chat-driven development with extra steps.
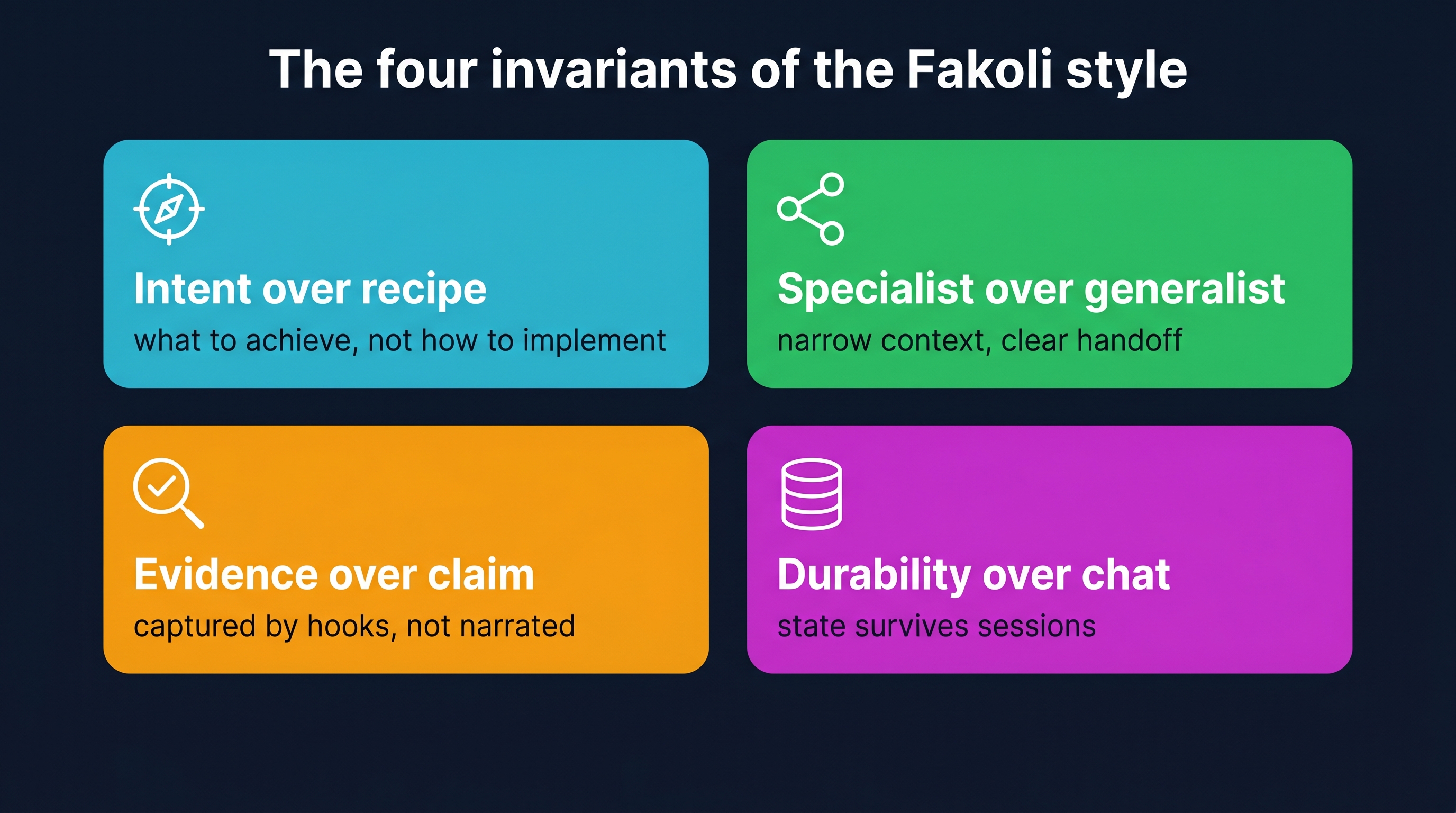
Intent over recipe. Plans describe what to achieve, not how to implement. Acceptance criteria are mandatory; line-by-line implementation code is forbidden. The agent reads the actual codebase before writing anything and adapts to what it finds.
Specialist over generalist. No single agent does everything. The architect designs the interface, the builder implements it, the integrator wires it in, the reviewer checks the diff, the validator runs the tests. Each agent has constrained tools, a constrained context, and a clear ownership boundary.
Evidence over claim. A task is not done because an agent says it’s done. A task is done because the commands ran, the files changed, and the exit codes match expectations — and those facts were captured by hooks at the boundary, not narrated by the agent after the fact.
Durability over chat. The PRD, the tasks, the claims, the evidence — these live in a database that survives session resets, model swaps, and runtime changes. Chat history is not a database. Markdown is not a database. The state layer is.
I’ll work through each in turn.
Intent Over Recipe
The temptation when you’re writing a plan for an AI agent is to write the plan you’d give to a junior engineer who’s never seen the codebase. You explain the data model. You sketch the function signatures. You write out the tests you want. You’re being thorough, and “thorough” is what professional planning looks like.
It’s also the wrong shape for an LLM agent.
The agent isn’t a junior engineer who’s never seen the codebase. The agent reads the codebase in the same session it implements the change. It sees the actual patterns, the actual utilities, the actual conventions. Every line of “how to implement” in your plan is a line that competes with what the agent is reading live. And the codebase is current; the plan is a snapshot from whenever you wrote it.
I made this point earlier in the series, and I’ve watched it play out across every project where I’ve changed the planning style. Plans went from 3,000 lines to 200. Implementation quality went up because the agent had room to adapt. Plan staleness went away because there was nothing in the plan to go stale.
The invariant is: write down what you want, write down how you’ll know it’s done, and leave the implementation to the layer that has the codebase in front of it.
Specialist Over Generalist
The fakoli-crew piece earlier in this series spent a lot of time on the specific archetypes, which I’m not going to re-litigate here. The invariant is the structural one underneath the archetypes.
A generalist agent that does everything has a problem you can’t solve by improving the prompt: context pollution. The same conversation that holds the architectural decisions also holds the implementation diffs, the review findings, the test output, the lint errors, the documentation drafts. By the third wave, the conversation is full of stale information that the agent can’t unsee.
A specialist crew breaks the context. Guido designs and writes a new module and that’s all guido’s context contains. Welder wires it into the existing system and that’s all welder’s context contains. Critic reviews the diff and the criteria, nothing else. When the wave ends, the contexts close. The next wave starts fresh.
This is the same reason you don’t have one engineer do architecture, implementation, integration, review, and QA at the same time on a real team. It’s not because the one engineer couldn’t do all of it. It’s because doing all of it at once means the architectural thinking happens while you’re worrying about test failures, and both jobs get worse.
The invariant is: split the work so that each agent has a narrow context and a clear handoff. The orchestration layer handles the handoff. The specialists handle the work.
Evidence Over Claim
The shortest way to describe what’s broken about “AI says it’s done” is that it’s a self-report from an actor who hasn’t been audited.
The longer way: a model that has been trained to be helpful will tell you it’s done before it’s done, will tell you the tests passed before it ran them, will tell you the build is green when it hasn’t tried. Not because the model is malicious. Because confident helpfulness scored well during training. The training selected for an actor who believes its own confident summaries.
That actor isn’t trustworthy on completion claims. It can be trustworthy with the right loop around it, but the right loop requires that the completion claim be checkable against system-captured evidence the actor didn’t produce.
Fakoli-state does this with hooks: every command the agent runs in the Bash tool gets captured by capture-evidence.sh as the work happens. When the agent submits, it cites which commands and which output to include from the buffer. The sentinel cross-checks the cite against the capture. If the agent claims it ran pytest and the buffer doesn’t show a pytest invocation, the discrepancy is logged and the apply gate refuses.
Almost every team I’ve seen running AI agents on production work has skipped this step. They run the agent, they read what the agent says, they trust the summary, they merge. It works most of the time. It fails in the cases that matter — the cases where the agent’s confident summary is the only thing standing between you and a broken build, and the summary is wrong.
The invariant is: capture evidence at the boundary, validate it before the work is done, and treat any self-report that doesn’t match captured evidence as a red flag.
Durability Over Chat
I spent two posts in this series on the state layer specifically, so I won’t re-argue it here. The condensed version:
If your project plan lives in chat history, you don’t have a project plan. You have notes that hopefully reflect what you wanted before the session ended. If your task list lives in a markdown file that gets rewritten on every wave, you don’t have task tracking. You have status snapshots that may or may not match what’s actually true. If your “claim” on a task is “I told the agent to work on this in the prompt,” you don’t have a claim model. You have a hope.
Durability is the precondition for trust between sessions, between agents, and between the human and the system. Without it, every session starts from zero. With it, the work compounds.
The invariant is: the things that matter for coordination — specs, tasks, claims, evidence — live in a database, not a conversation.
What the Model Enables
When you assemble the four invariants into a working system, three things become possible that weren’t possible before. I want to name them specifically, because they’re the reasons I think this matters beyond my own workflow.
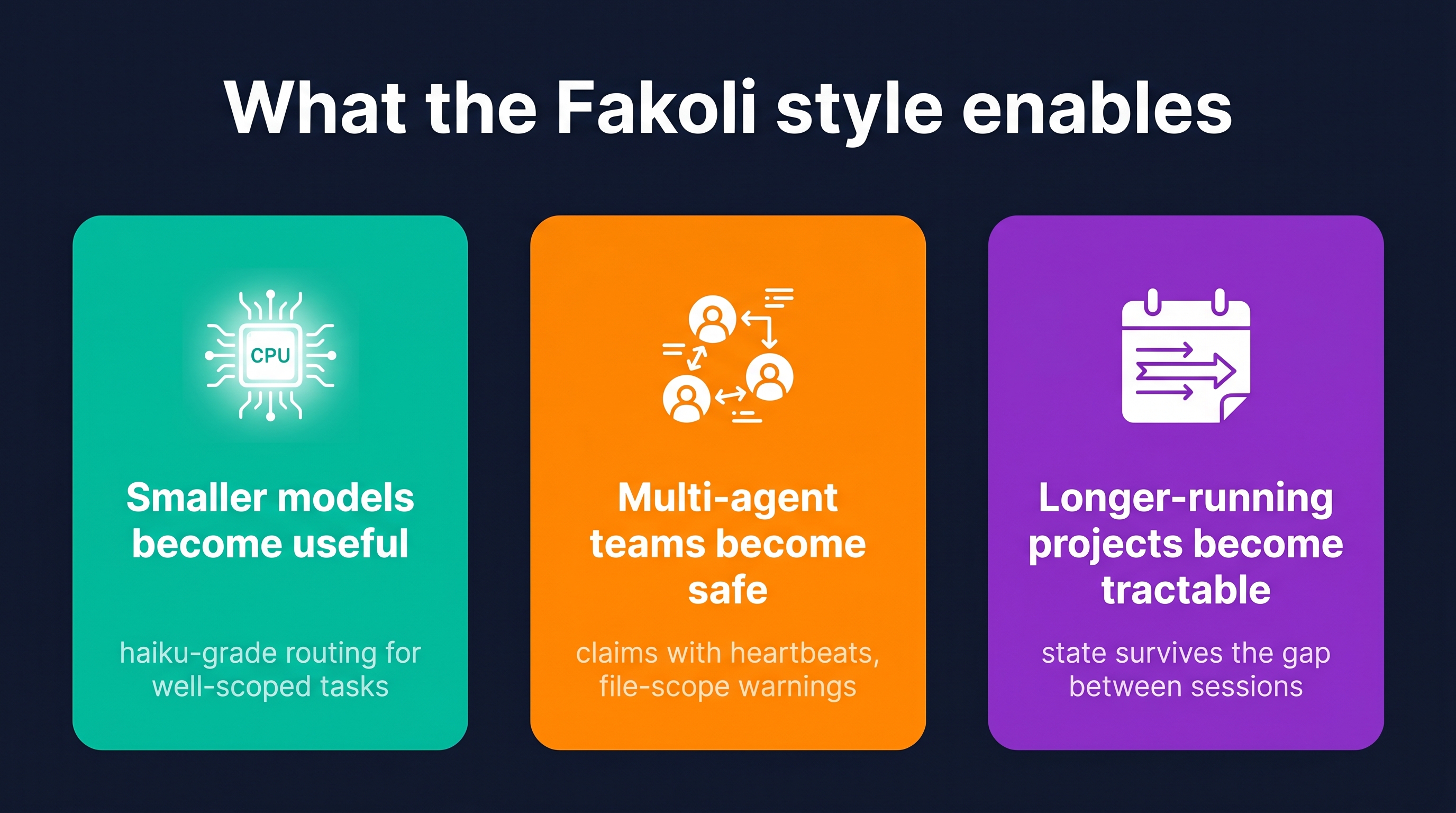
Smaller models become useful. Most of the AI coding work I see assumes you’re running a frontier model — Claude Opus, GPT-5, Gemini 2.5 Pro. That’s expensive, and it’s overkill for a lot of work. With intent-driven plans, evidence-captured loops, and well-scoped work packets, smaller models can execute tasks that would have required a frontier model when the prompt was vague and the context was the whole codebase. Haiku can handle a task where the work packet says exactly what to do, the acceptance criteria say exactly what passes, and the verification command says exactly how to check. That’s not a hypothetical — that’s agent_suitability scoring routing work to the cheapest model that can do it.
Multi-agent teams become safe. The reason two agents on the same codebase usually doesn’t work is that they have no coordination model. They overwrite each other, they duplicate work, they invalidate each other’s assumptions. With claims, leases, file-scope warnings, and evidence captured per claim, multi-agent dispatch becomes a real thing — not because the agents got smarter but because the coordination layer got real.
Longer-running projects become tractable. The hardest thing about agentic development isn’t a single session. It’s the fifth session, two weeks after the first one, where you need to know what you decided last time, why, and what’s still open. Chat history loses this. A state layer doesn’t. The PRD is still parseable; the decisions log is still queryable; the work that’s already done is recorded; the claims still in flight are visible. The project survives the gap between sessions because the state did.
What’s Still Open
I want to be honest about what hasn’t worked yet, because the model has limits and I’d rather name them than pretend.
The model assumes a senior orchestrator. When I dispatch a wave and walk away, the quality of the outcome depends on the quality of the spec I wrote and my judgment when reviewing the verdict. The framework is leverage on a competent person. It is not a replacement for one. I haven’t yet figured out how to make this work for a junior engineer who wants the agents to design the spec for them — and I’m not sure the answer is “improve the framework” rather than “this is a tool for a different audience.”
Team coordination is unproven. Everything I’ve built has been validated by me running the system on my own projects. The model says multiple humans and multiple agents should coordinate around shared state. I’ve simulated this with multiple Claude Code sessions. I haven’t run it with multiple actual humans on a real team. The state file design supports it. The sync providers project it to GitHub Issues for human-only collaborators. But I haven’t watched the failure modes yet, and I assume there are some.
Evaluation is informal. I don’t have a rigorous benchmark that says fakoli-flow plus fakoli-crew plus fakoli-state outperforms raw Claude Code by N percent on M tasks. I have my own felt sense — that the bugs caught per critic pass are real, that the rework cycles are shorter, that the projects I’ve shipped with the full stack are higher quality than the ones I shipped without it. That’s not nothing. It’s also not a study. The next phase of this work is building those evals so that “the Fakoli style is better” is a measurable claim, not a personal one.
The Principle That Survives Everything Else
The last thing I want to leave is the principle that’s underneath all of this, because I think it’s the most portable.
I came up through twenty years of infrastructure engineering. The lesson I kept relearning across every system I built — distributed databases, AWS multi-region, multi-cluster Kubernetes, the Terraform deployments for all of it — is that the architecture matters less than the discipline. You can build a beautiful system with no discipline and watch it become a swamp in eighteen months. You can build a clunky system with sharp discipline and watch it stay maintainable for a decade.
Discipline is what survives when the team grows, the requirements change, and the original architects move on. Discipline is the thing that gets encoded into the system so it doesn’t have to live in every individual’s head.
Agentic development has the same property and most people are missing it. The agents are getting better. The runtimes are getting better. The IDEs are getting better. Everyone is improving the tools. Almost nobody is improving the discipline.
The Fakoli style is one attempt at that. Intent over recipe, specialist over generalist, evidence over claim, durability over chat. Encoded into plugins so the discipline isn’t optional — so the workflow doesn’t proceed unless the spec is reviewed, the agent has claimed the task, the evidence is captured, and the apply gate passes.
You don’t need my plugins to apply the four invariants. You can implement them yourself, in any agent platform, in any language. The plugins are how I encoded the discipline for myself. The invariants are the part that matters.
If you take one thing from this series, take that. Workflow without discipline is a faster typewriter. Discipline encoded into the system is what turns AI agents from impressive demos into infrastructure you can build a career on.
That’s what I’ve been building. That’s what fakoli-state was the missing piece of. And that’s the bet I’m placing on what serious agentic engineering looks like when the dust settles.
Co-authored with AI, based on the author's working sessions, dictations, and notes.
Explore the source
fakoli/fakoli-plugins
This article discusses an open-source project. Star it, fork it, or open an issue.